AWS RDS
- RDS : 관계형 데이터베이스
- AWS RDS : AWS RDS 인스턴스에 DB를 생성할 수 있고, 올려진 DB는 AWS에 의해 관리됨
- RDS Type
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Aurora
- EC2가 아닌 RDS에 DB서비스를 배포하는 이유
- DB 프로비저닝과 기본 운영체제 패치가 자동화 되어 있음
- 지속적으로 백업 생성 -> 특정 시점으로 복원 가능
- 대시보드에서 성능 모니터링 가능
- 읽기 전용 복제본을 활용하여 읽기 성능을 개선할 수 있음
- 재해 복구 목적으로 다중 AZ 설정 가능
- 수직 확장 및 읽기 전용 복제본 생성을 통한 수평 확장 가능
- 파일 스토리지는 EBS에 구성 -> RDS와 연결될 Storage를 의미
- EC2 인스턴스에 DB를 배포할 때 설정할 모든 것들을 AWS에서 제공
SSH로 접근할 수 없다는 단점이 있음
RDS는 EC2기반 -> RDS 생성 시, EC2 설정처럼 CPU, RAM 등 스펙을 설정할 수 있음
RDS는 DB서버이고, 실제 데이터 저장은 EC2의 EBS에 저장됨 (RDS도 EC2 기반이기 때문)
Connectivity 설정을 이용하면 Security Group 설정이나 VPC 등 세부적인 네트워크 설정을 자동으로 해주기 때문에 별도 설정 필요 없이 EC2와 연결할 수 있음 (EC2 외의 다른 컴퓨터에서 접근할 경우, 세부 네트워크 설정 필요)
Storage Auto Scaling : DB에 데이터가 많이 쌓이면 공간이 부족해질 수 있는데, RDS가 이를 감지해서 자동으로 스토리지(EBS) 용량을 확장해줌
- 스토리지(EBS) 용량 확장을 위해 DB 다운이 필요하지 않음
- 최대 스토리지 임계값을 설정해야 함 (확장 최대값)
- 남은 공간이 10% 미만이 되면 스토리지를 자동으로 수정
- 스토리지 부족 상태가 5분 이상 지속되면 스토리지를 자동으로 수정
- 지난 수정으로부터 6시간이 지났을 경우에 스토리지를 자동으로 수정
- workload를 예측할 수 없는 application에 유용함
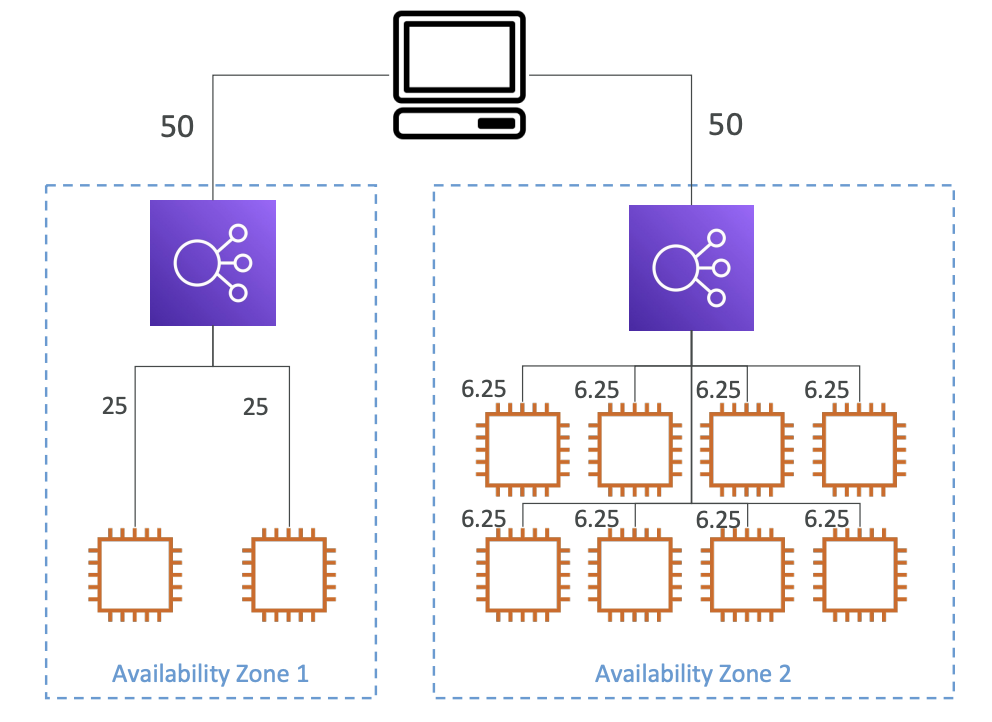
RDS Read Replicas for real scalability (RDS 읽기 전용 복제본)

- 특징
- 최대 15개까지 생성
- 동일 가용영역, 여러 가용영역, 여러 Region에 걸쳐 생성될 수 있음
- Main RDS와 비동기식 복제가 진행됨 -> Main RDS에 write하고 읽기전용 RDS를 읽을 경우, 일관적인 데이터 수집 가능
- DB로 승격 가능 -> 자체적인 생애 주기를 가짐
Use Case : 특정 application의 DB에 대한 데이터 분석이 필요한 경우, Main RDS에 직접 접근하여 데이터를 추출하면 application이 느려질 수 있음 -> 읽기전용 Replica를 생성하여 데이터 분석용으로 제공하면 application에 대한 영향도를 없앨 수 있음
Network Cost
- 특정 가용영역에서 다른 가용영역으로 데이터가 이동할 때 비용 발생 -> 관리형 서비스는 예외 (RDS 읽기 전용 복제본은 관리형 서비스) -> 다른 가용영역이나 동일 region내에 읽기전용 복제본이 있을 경우, 비용이 발생하지 않음
- RDS 읽기 전용 복제본이 다른 Region에 존재하는 경우, 네트워크에 대한 데이터 복제 비용 발생
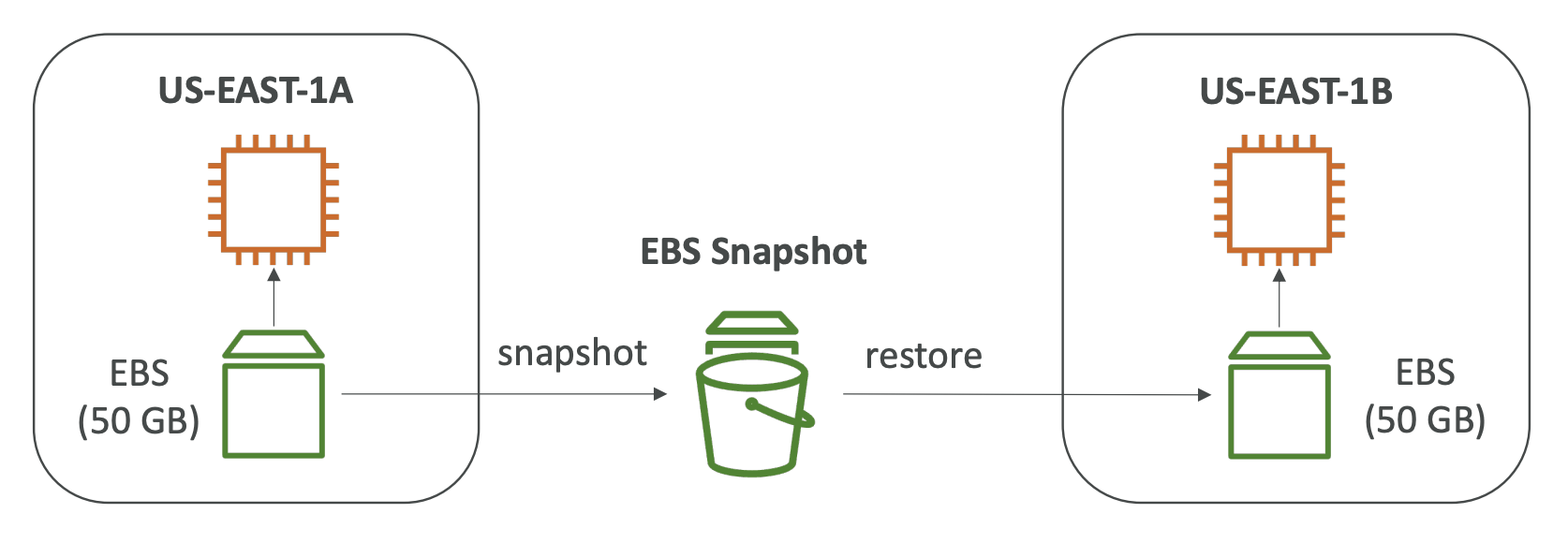
- RDS Multi AZ (Disaster Recovery)
- Master DB의 모든 변화를 동기적으로 RDS standby 인스턴스에 복제 (RDS standby 인스턴스는 다른 가용영역에 생성)
- Master DB에 문제가 발생할 때, standby RDS에 자동으로 장애 조치가 수행됨 (standby가 임시적으로 master가 됨) -> 하나의 RDS DNS를 갖고있기 때문에 가능 (RDS DNS는 DB의 엔드포인트가 됨)
- standby RDS는 오직 장애에 대비한 대기 목적만 수행 (평시에는 사용 불가)
- standby RDS로 읽기전용 복제본을 생성할 수도 있음

- Single-AZ to Multi-AZ
- 다운타임이 없음 (DB 중지 필요x)
- DB 설정에서 Multi-AZ 활성화 시, 다른 가용영역에 Standby DB가 자동으로 생성됨
- 내부적으로 발생하는 일
- RDS의 Snapshot 생성
- 생성된 Snapshot은 새롭게 생성된 Standby DB에 복원됨
- Main-Standby간 동기화가 설정됨
RDS Custom
- RDS에서는 운영체제 및 데이터베이스 관리자 권한 기능에 접근하지 못함 -> RDS Custom에서는 가능 (Oracle, Microsoft SQL Server)
- SSH 활용 접근
- Custom 기능
- Configure Settings
- Install Patches
- Enable Native Features
Amazon Aurora
- 특징
- postgres 및 MySQL 호환 (해당 DB의 드라이버만 사용 가능) - Aurora MySQL, Aurora P ostgreSQL
- AWS 고유 기능
- 클라우도 최적화 (MySQL보다 5배 높은 성능, Postgres보다 3배 높은 성능)
- Storage 자동 확장 (10GB, up to 120TB)
- 기본적으로 클라우드 네이티브 환경이므로 빠른 장애 조치 (its HA native)
- 비용은 RDS에 비해 20% 높음
- BackTrack : 특정 시점으로 데이터 복원하는 기능 (백업에 의존하지 않고 다른 기능 활용)
- High Availability
- 3개 가용영역에 걸쳐 6개의 데이터 사본 저장 (AZ하나가 비정상이어도 괜찮음)
- 일부 데이터에 문제가 있을 경우, P2P 복제를 통한 자가복구 과정이 있음
- 단일 볼륨이 아닌 수백 개의 볼륨을 활용 (AWS에서 관리)
- RDS의 multi-AZ와 유사
- master DB가 작동하지 않으면 30초 이내로 자동 장애복구 진행 (작은 블록 단위로 자가복구, master DB 변경 등)
- master DB에 문제가 생기면 읽기 전용 DB중 하나가 master가 될 수 있음
- region간 복제 지원
- 읽기 전용 복제본은 15개까지 가능, 복제 속도도 상대적으로 빠름 (MySQL은 5개까지)

- Aurora DB Cluster
- master가 바뀌거나 장애조치를 대비하여 writer Endpoint 제공 (DNS로 항상 master를 가리킴)
- 읽기 전용 DB의 자동 Scaling이 진행됨 (적절한 인스턴스 수 유지, CPU사용량/인스턴스 평균 연결 수 기반)
- Reader Endpoint (인스턴스 전용 Endpoint와 다른 개념)
- connection load balancing : 모든 읽기전용 인스턴스와 자동 연결
- client가 Reader Endpoint로 요청 시, 다중 읽기전용 인스턴스 중 하나로 자동 연결
- load balancing은 connection 레벨에서 진행됨
- 크기가 큰 global Aurora 인스턴스인 경우, Aurora Cluster내에 다른 region을 추가할 수 있음

- Aurora Auto Scaling

- Custom Endpoints
: db.r3.large, db.r5.2xlarge 두 종류의 읽기전용 Aurora 존재 -> Aurora 인스턴스 일부를 Custom Endpoint로 정의 -> Custom Endpoint에는 성능이 더 좋은 db.r5.2xlarge 인스턴스를 연결하여 application 단에서 해당 Custom Endpoint에는 많은 연산이 필요한 쿼리를 날릴 수 있도록 할 수 있음 -> custom endpoint를 만들기 시작하면 reader endpoint를 사용할 것이 아닌 남은 인스턴스를 연결한 Custom Endpoint를 생성해줘야 함.

- Serverless (다시 봐야함)
: 간헐적이고 예측 불가능한 업무량에 대응 -> capacity planning 불필요 -> 초당 비용을 지불하는 것이 효율적

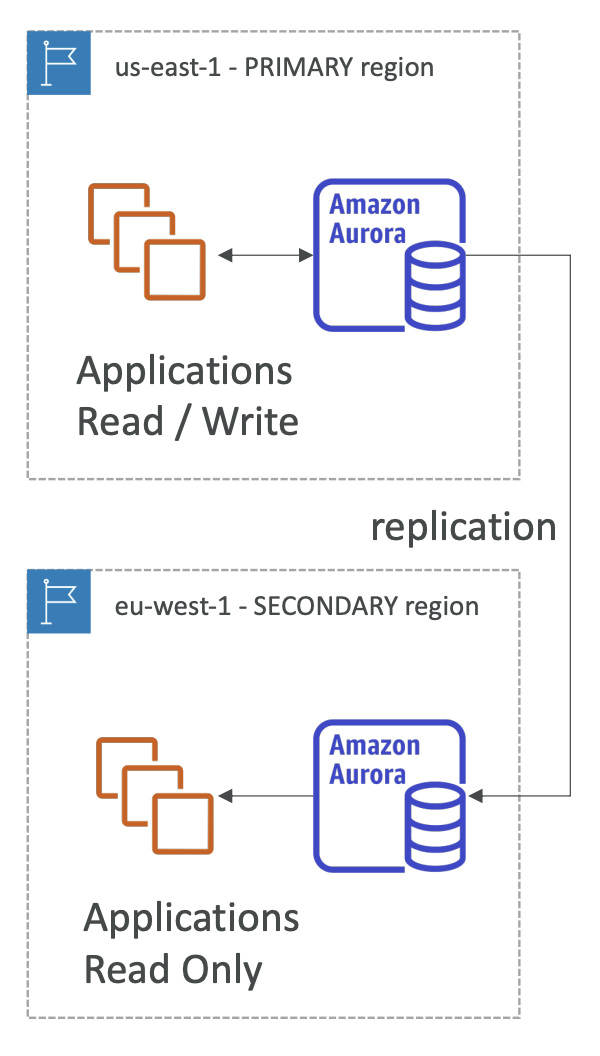
- Global Aurora
- 리전간 읽기전용 복제 가능 (읽기/쓰기 가능 primary region, 최대 5개 읽기 전용 secondary region, 보조 region당 최대 16개 읽기 전용 인스턴스) -> global한 읽기 요청에 대한 응답 지연 감소에 도움됨
- 특정 region에 장애가 생겼을 경우, 다른 region으로 primary region전환 재해복구 (복구시간 1분 이내)
- 특정 region에서 다른 region으로 데이터 복제 시, 1초 이하의 시간 소요
- Aurora Machine Learning
: Aurora활용 Machine Learning 예측 기능을 application에 추가할 수 있음
- Supported Service
- SageMaker : 어떤 종류의 기계학습 모델이라도 사용할 수 있게 해줌
- Comprehend : 감정 분석
- Use case
- 이상행위 탐지
- 광고 타겟팅
- 감정 분석
- 상품 추천
- etc...

RDS Backups
- 매일 자동으로 백업 수행 (during backup window)
- 5분마다 트랜잭션 로그 백업
- 백업 보존기간은 0~35일 사이로 설정 가능
- 수동 DB Snapshots => 원하는 기간동안 백업 유지 => 비용절감으로 사용할 수 있음 (ex. 한달에 두시간만 사용하는 DB를 Snapshot으로 백업해 둔 후, 원본 DB는 완전히 내려서 비용 절감)
Aurora Backups
- 자동화된 백업 (1~35일) => 비활성화 불가
- 해당 기간의 어느 시점으로든 백업 가능
- 수동 DB Snapshot은 RDS Backups과 동일
RDS/Aurora Restore Options
- 자동화된 백업이나 수동 snapshot으로 DB 복원 가능
- S3에서 MySQL로 복원 가능 (ex. 온프레미스의 DB를 S3에 백업 -> S3에서 RDS로 DB 복원 -> 온프레미스에서 RDS이동 가능)
- 온프레미스->Aurora로 복원을 위해서는 외부적으로 Percona XtraBackup 소프트웨어 사용 필요 -> 해당 소프트웨어로 온프레미스 DB의 백업파일을 S3로 보낼 수 있음
Aurora DB Cloning
- 기존 DB cluster -> 새로운 Aurora DB cluster 생성 가능
- Use case : 운영환경의 데이터로 테스트를 진행하고 싶을 때 활용 가능 (운영환경 데이터를 개발환경 DB에 이동) -> 운영환경 Aurora DB 복제 (Snapshot 생성 후, 복원하는 것보다 훨씬 빠름 -> copy-on-write 프로토콜 사용하기 때문)
- 일반 DB 복제는 원본과 복사본이 같은 스토리지를 공유 -> Aurora DB Cloning은 스토리지까지 복제하는데 RDS에 비해 빠르기까지 함
RDS Security
- DB가 처음 실행될 때, 원본과 복사본이 AWS KMS를 활용하여 모두 암호화됨
- 원본 DB가 암호화되지 않았다면, 복사본도 암호화할 수 없음
- 암호화 type
- in-flight encryption : TLS 인증서 필요, client와 DB간의 전송 중 데이터 암호화
- IAM Authentication : username/password 대신에 IAM Role을 활용하여 DB에 접근할 수 있음
- Security Groups : DB에 대한 네트워크 접근 통제 가능 (방화벽과 유사)
- RDS/Aurora에 SSH 접근 불가 (AWS에서 관리하기 때문, RDS 커스텀 서비스를 사용한다면 예외)
- 감사 log : 시간에 따라 어떤 쿼리가 생성되고 있는지 확인 가능 (로그의 장기간 보관을 위해서는 CloudWatch 서비스 활용 필요)
RDS Proxy

- 완전 관리형 RDS DB Proxy 배포 가능
- Why proxy?
- application이 DB내에서 connection pool을 생성하고 타 app과 공유할 수 있음 (proxy가 하나의 pool에 연결을 모음) -> RDS로의 직접 연결을 줄일 수 있음 -> 연결이 많은 경우 CPU, RAM과 같은 컴퓨팅 리소스에 부담이 생길 수 있음
- DB로의 private 접근
- DB timeout 최소화
- RDS Proxy는 완전히 서버리스
- Auto Scaling이 가능하여 용량 관리가 불필요하고 가용성이 높음 (multi-AZ)
- 장애 조치 시간을 최대 66%까지 줄일 수 있음 (How?) -> main RDS 인스턴스에 app들 을 모두 연결하고 장애조치를 모두 처리하게 하는 것이 아닌, 장애 조치에 무관한 app들은 proxy에 연결 -> app코드를 모두 수정하지 않아도 되고, 장애조치가 끝난 후 proxy에 연결만 하면 되어서 장애조치 시간이 감소됨
- EC2 인스턴스간 connection pool을 공유하기 때문에 연결 시간을 아낄 수 있음
- MySQL, PostgreSQL, MariaDB용 RDS/MySQL, PostgreSQL용 Aurora 지원
- DB에 IAM 인증을 강제함 -> IAM인증을 통해서만 DB 인스턴스에 접근할 수 있음
- RDS Proxy는 public에서 접근할 수 없음 (VPC내에서만 접근 가능)
- Lambda Functions : RDS Proxy와 사용하기 좋음 (Lambda는 여러 개가 생성되고 사라지는 속도가 매우 빠름 -> RDS 인스턴스에 직접 접근하면 연결에 timeout 발생 가능성이 높아짐) -> Lambda Function이 RDS Proxy를 overload함 -> RDS 인스턴스로의 직접 연결이 줄어듦
ElasticCache
RDS가 관계형 DB를 관리하는 방식과 동일
캐싱기술인 Redis나 Memcached를 관리
캐시를 이용하면 매번 DB에 접근하지 않아도 빠른 데이터 조회 가능
application의 상태 또한 저장하여 관리할 수 있음
AWS가 서비스를 관리 (OS패치, 최적화, 설정, 구성, 모니터링, 장애복구, 백업 등)
캐싱서비스 사용 = application 코드 변경 (DB가 아닌 캐시를 쿼리하도록)
캐시 무효화전략(=캐시삭제) 필요 (가장 최신 데이터만 사용되어야 하기 때문)
Architecture
- application -> cache에 사전 쿼리 이력이 있는지 확인 (있다면 cache hit라고 부름)
- 쿼리 이력이 있다면(cache hit), 쿼리에 대한 응답을 캐시저장소로부터 받아옴
- 쿼리 이력이 없다면(cache miss), DB에 쿼리를 날려 데이터를 가져옴
- 해당 쿼리와 응답을 캐시저장소에 저장

- 사용자 세션(상태) 저장 Architecture
- 사용자가 어떤 application에 로그인하면, application은 세션데이터를 캐시저장소에 write
- 사용자가 app의 다른 인스턴스로 redirect되면, 해당 app은 요청 사용자에 맞는 세션데이터를 캐시저장소로부터 조회해 옴 (사용자 로그인 유지) => app이 직접 세션을 저장할 필요가 없기 때문에 상태 비저장 app 구현 가능

- Redis vs Memcached
- Redis (장점, 데이터 내구성/가용성)
- 자동 장애 조치 기능이 있는 Multi-AZ
- 읽기 복제본 가능 (RDS와 매우 유사)
- AOF(?)를 이용한 데이터 지속성
- 백업 및 복원 기능
- keyword : set, sorted set 지원(?)
- Memcached (분산되어 있는 순수 캐시)
- 데이터 분할(paritioning)을 위해 멀티 노드 활용 (sharding)
- 고가용성x, 복제x, 영구 캐시x
- 백업x, 복원x
- 멀티스레드 아키텍처
Cache Security
- Redis
- Redis만 IAM 인증 지원 (나머지는 username/password)
- Redis AUTH : Redis 인증을 위한 password와 token 생성 -> 캐시에 추가 보안 제공, Redis 보안그룹에 해당 pwd와 토큰을 인증해야 함
- SSL 전송중 암호화 지원
- Memcached
- SASL 기반 인증 제공
ElasticCache 패턴
- Lazy Loading : 모든 read 데이터 캐싱 -> 조회 지연 발생
- Write Through : DB에 데이터가 기록될 때마다 캐시에 데이터를 추가하거나 업데이트
- Session Store : 세션 유지시간을 사용하여 만료 시 캐시 데이터 삭제
- Redis Use Case : Gaming Leader Board (아래 기능 활용)
- Redis Sorted Sets : 고유성과 순서를 보장 (요소가 추가될 때마다 실시간으로 순위를 매김)

'개발 > AWS' 카테고리의 다른 글
| [AWS] Solution Architecture (0) | 2024.05.19 |
|---|---|
| [AWS] Route 53 (0) | 2024.05.18 |
| [AWS] Auto Scaling Group (ASG) (0) | 2024.05.06 |
| [AWS] Load Balancer (0) | 2024.05.06 |
| [AWS] EC2 (3) (0) | 2024.05.03 |