CloudWatch Metrics
Metrics : AWS 서비스를 모니터링하기 위한 변수 값 (ex. CPUUtilization, Networkln...)
특징
- 각 Metric은 각기 다른 namespace에 저장 (AWS 서비스당 namespace는 1개)
- Dimension : 측정 기준, metric의 속성 (instance id, environment, etc...)
- metric당 최대 측정 기준은 30개
- metric은 timestamp가 필수
- 많은 지표를 한번에 볼 수 있는 CloudWatch dashboard가 있음
- Custom Metrics를 만들 수도 있음 (ex. EC2인스턴스의 Memory 사용량)
- CloudWatch Metric Streams : CloudWatch 외부로 스트리밍하는 기능
- 원하는 AWS 서비스에 실시간 저지연 성능으로 Metric을 전달할 수 있음 (Kinesis Data Firehose, 타사서비스 등)
- 모든 namespace의 metric을 전달하거나, 특정 namespace만 선택하여 metric을 전달할 수도 있음

CloudWatch Logs
CloudWatch Logs : AWS의 app log를 저장할 수 있는 서비스
Log groups : app log를 저장할 group, 이름은 보통 app의 이름으로 설정
Log stream : app안의 인스턴스나 log files, containers 형태로 존재
특징
- log 만료정책 정의 (1일~무한대)
- 다양한 서비스로 log를 보낼 수도 있음
- 모든 log는 암호화됨 -> KMS기반으로 암호화 설정 가능
- CloudWatch에 Log 전송 방법
- SDK
- CloudWatch Logs Agent
- CloudWatch Unified Agent
- Elastic Beanstalk : app으로부터 직접 log를 수집하고 CloudWatch에 전송
- ECS : Container로부터 log를 수집하여 CloudWatch에 전송
- AWS Lambda : 해당 서비스 자체적으로 log 전송
- VPC Flow Logs : VPC 메타데이터 트래픽 log 전송
- API Gateway : 해당 서비스로 오는 요청에 대한 log를 모두 전송
- CloudTail : 필터에 기반하여 직접 log 전송
- Route53 : 모든 DNS쿼리에 대한 log 전송
- CloudWatch Logs Insight 기능을 이용하여 log에 쿼리를 할 수 있음 -> 로그 데이터 검색 및 분석 가능 -> console상에서 샘플 쿼리 제공 -> CloudWatch 대시보드에 적용할 수도 있음 -> 다수의 log group을 쿼리할 수도 있음 -> 과거 데이터만 쿼리 가능
- S3 Export : Batch Export, 최대 12시간 소요, CreateExportTask API 활용

- CloudWatch Logs Subscriptions
- log를 실시간으로 받아서 분석할 수 있음
- Kinesis Data Streams, Kinesis Data Firehose, Lambda 등에 보낼 수 있음
- Subscription Filter 기능을 활용하여 내보내려는 대상 log를 선별하여 보낼 수 있음
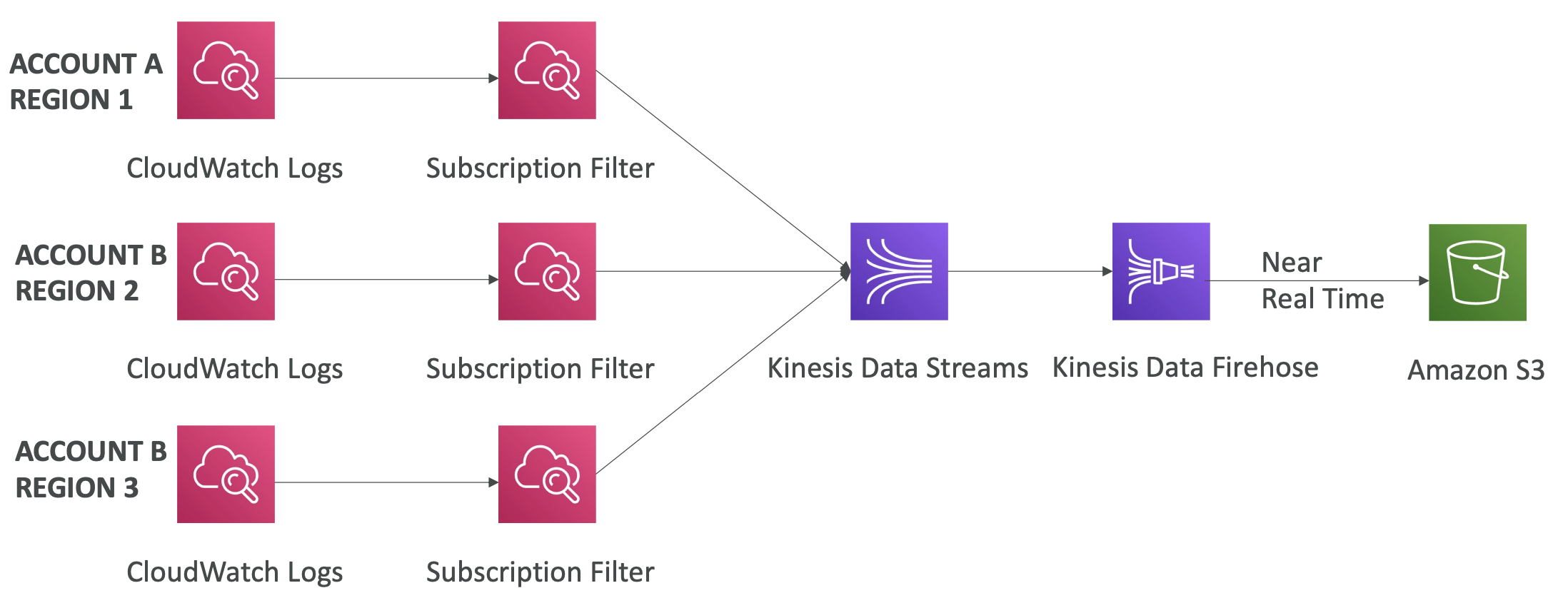
- 원리 : Sender계정에서 Recipient계정의 서비스로 log를 보낼 때, Sender 계정에서는 Subscriptions Filter를 활용하게 되고, Recipient 계정에서는 가상의 Subscription Destination을 만들어 데이터를 받아 대상 서비스로 전달 -> Destination Access Policy를 통해 Subscriptino Filter를 허용해야 함 -> Subscription Destination에서 Kinesis 서비스로 접근하기 위한 IAM Role 생성 필요


- Aggregation Multi-Account & Multi-Region : CloudWatch Logs Subscriptions 기능 활용 -> 다양한 계정 및 다양한 region에서 온 CloudWatch Logs 데이터를 특정 계정의 하나의 Kinesis Data Streams 등에 통합할 수 있음
- LiveTail : Log Stream으로 전송된 log들을 실시간으로 console UI에서 확인할 수 있음
CloudWatch Agent
- 기본적으로 EC2에서는 CloudWatch로 어떤 log도 옮기지지 않음 -> EC2에 CloudWatch Agent를 실행시켜 CloudWatch로 push해야 함
- EC2 -> CloudWatch로의 IAM Role 생성 필요
- CloudWatch Agent는 온프레미스에서도 실행가능
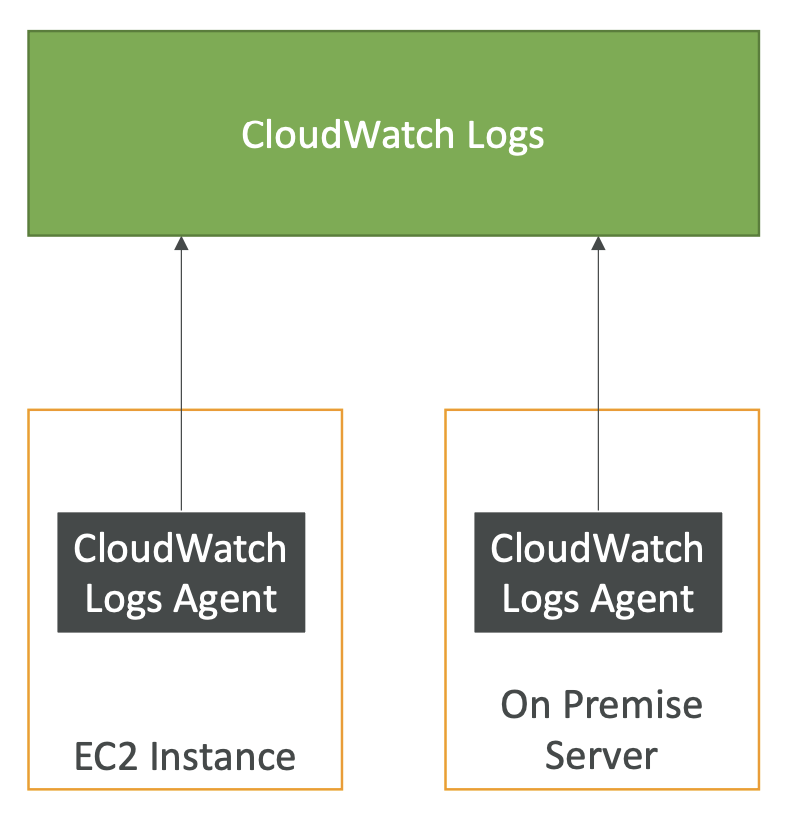
- CloudWatch Logs Agent (older)
- EC2나 온프레미스 서버를 위한 Agent
- CloudWatch logs로 log만 보냄
- CloudWatch Unified Agent (통합 Agent, newer)
- EC2나 온프레미스 서버를 위한 Agent
- log만 보낼 뿐만 아니라 프로세스나 RAM과 같은 시스템 레벨의 metrics도 수집 -> CloudWatch logs에 통합 전송
- Metric과 log 둘다 활용
- SSM Parameter Store를 이용하여 Agent를 보다 쉽게 구성할 수 있음 -> 중앙 집중형으로 설정 가능
- CloudWatch Unified Agent - Metrics
- 수집 metric
- CPU
- DISK
- RAM
- Netstat
- Processes
- Swap Space
- 일반적인 EC2 모니터링 기능보다 더 많은 metric을 수집함 (좀더 세부적인 metric 수집 가능)
CloudWatch Alarms
CloudWatch Alarms : Metric에서 나오는 알림을 트리거함 (샘플링, 퍼센티지, 최대, 최소 등 정의 필요)
Alarm 상태
- OK : 알람이 트리거되지 않음
- INSUFFICIENT_DATA : 상태를 결정하기 위한 충분한 데이터가 없음
- ALARM : 기준 값을 초과하여 알림 전송
Period : 얼마나 오랫동안 Metric을 평가할지? (10s, 30s, 60s의 배수 등)
Alarm Targets
- EC2 인스턴스에 대한 동작 (Stop, Terminate, Reboot 등)
- Auto Scaling에 대한 동작 (Scale-out, Scale-In 등)
- SNS에 알림 전송 (SNS를 Lambda와 연결하여 알림에 대한 동작까지 정의할 수 있음)
- Composite Alarms
- 기본 CloudWatch Alarm은 싱글 metric 기반
- 다수의 metric 기반일 경우, Composite Alarm 사용 필요 -> 다수의 다른 알람들의 상태를 모니터링하는 방식
- 다른 알람들의 상태를 모니터링하면서 AND 또는 OR로 최종 상태 결정
- 알람 노이즈를 줄이는 데 유용

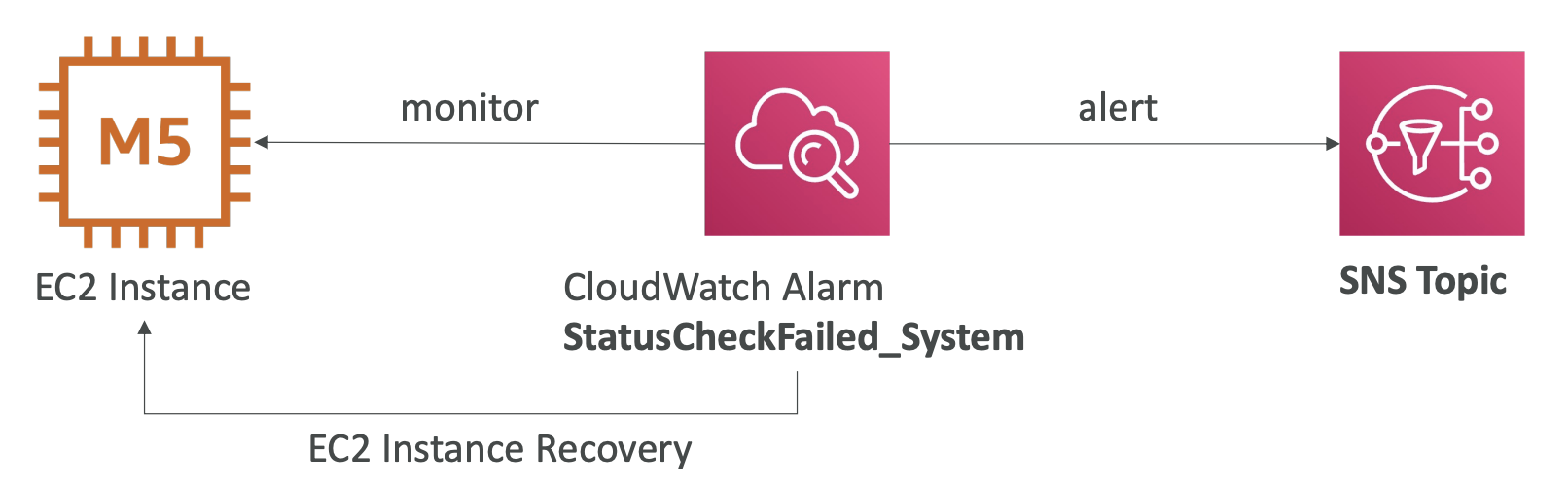
- Use case : EC2 Instance Recovery
- EC2 VM과 연관된 Instance status와 하드웨어와 연관된 System status 두 가지의 상태를 검사할 수 있음
- 위 두가지 상태 검사에 대해 CloudWatch Alarms을 정의할 수 있음
- 해당 알람이 발생하면 EC2 인스턴스 Recovery를 시작
- 복구가 완료되면 SNS에 알림을 전송함으로써 복구완료를 알림
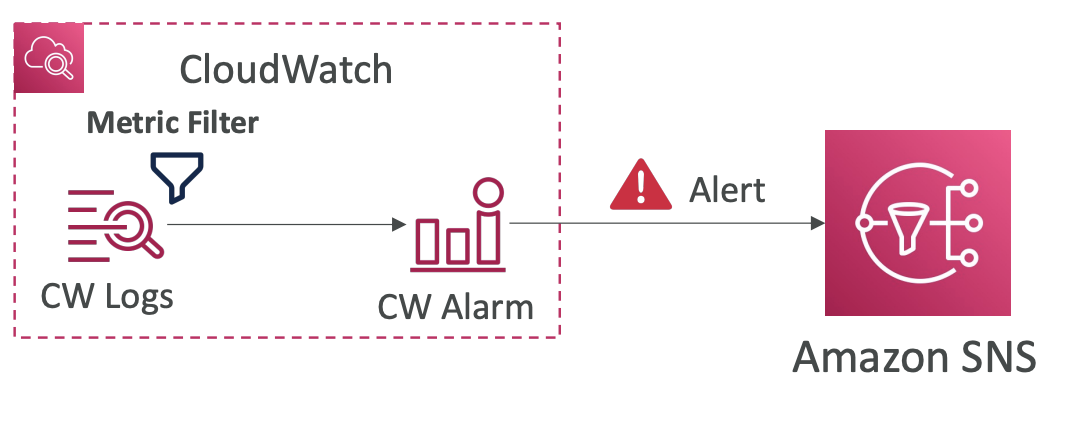
- Good to know
- Metric Filter 기반의 Alarm을 생성할 수 있음 (ex. error와 같은 키워드를 많이 받은 경우에 Alarm을 발생시킴)
- 알람 테스트를 위해 set-alarm-state라는 CLI 호출 사용 가능
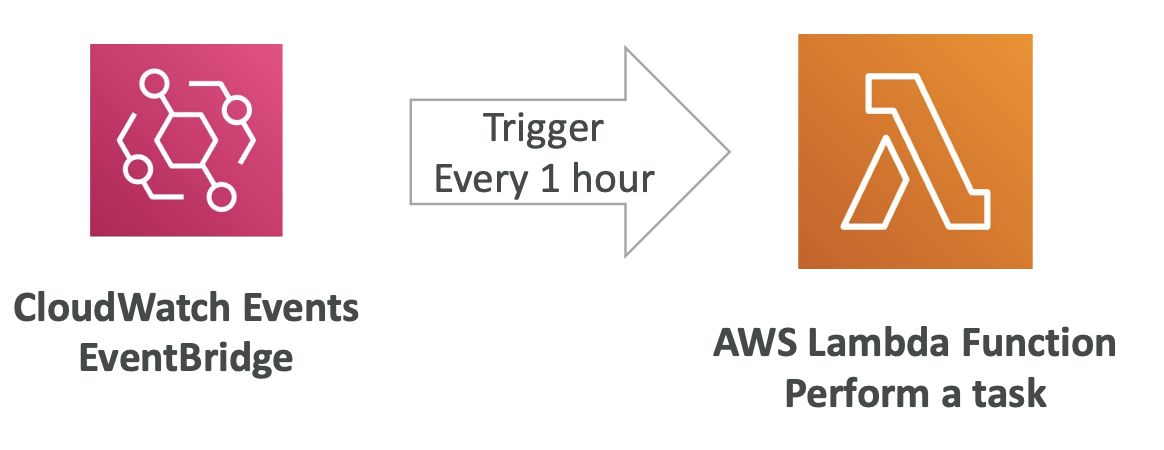
EventBridge (formerly CloudWatch Events)
- 활용 유형
- Schedule : Cron jobs

- Event Pattern : 특정 패턴의 이벤트를 감지하여 정의된 서비스를 수행 (ex. root 계정 login 시, 이벤트를 감지하여 SNS Topic에 알림을 전송 -> 해당 알림을 받은 서비스가 이메일 발송)

- Trigger Lambda : Lambda Function을 트리거할 수도 있음 (ex. 다수의 사용자에게 알림을 보내야 할 때, Lambda를 Trigger하여 다수 사용자가 구독 및 polling하는 SNS/SQS 알림을 발송하도록 함)
- EventBridge Rules
- filter 설정 : S3 Bucket중 특정 Bucket의 이벤트만 수신
- 여러 AWS 서비스가 source가 될 수 있음 + cron job
- 발생된 이벤트를 EventBridge가 수신하면, JSON문서를 생성함 (JSON에는 이벤트가 발생한 인스턴스 유형과 인스턴스ID등의 정보가 담겨있음)
- Destination 서비스에는 생성된 JSON을 전달함

- EventBridge Types
- Default Event Bus : 위에서 살펴본 Bus
- Partner Event Bus : 파트너사의 소프트웨어에서 발생한 이벤트도 수신 가능
- Custom Event Bus : 자체적으로 만든 app에서 발생한 이벤트를 수신 가능
- 특징
- 리소스 기반의 정책을 통해 다른 계정의 Event Bus에도 접근할 수 있음
- 이벤트를 저장할 수도 있음 (모든/필터링된 이벤트 대상, 기간은 설정 가능) -> 저장된 이벤트를 다시 재생할 수 있음 (ex. Lambda Function의 버그를 수정하고 이벤트를 다시 발행)
- Schema Registry
- 스키마 기반으로 App 코드 생성 가능
- Event Bus의 데이터가 어떻게 정형화되는지 알 수 있음 (to JSON)
- EventBrdige가 Event Bus로부터 어떻게 스키마를 추론하는지? 데이터는 어떻게 정형화하는지 파악 가능 -> JSON 데이터에 어떤 데이터가 어떤 데이터형식으로 구성되어 있는지 -> 해당 스키마를 통해 Java/Python 등 이벤트를 전송 받는 app 코드 생성 가능
- 스키마 Versioning 가능 -> 스키마 반복 가능

- Resource-based Policy
- 특정 Event Bus의 권한을 관리할 수 있음 (ex. 다른 region의 이벤트 허용/거부, 다른 계정의 이벤트 허용/거부 등)
- Use case : AWS Organization에 Event Bus를 두고 모든 계정의 Event를 하나에 수집 -> 리소스기반 정책 추가 필요

CloudWatch Insight
- CloudWatch Container Insight
: Container로부터 Metric과 log를 수집/집계/요약하는 서비스
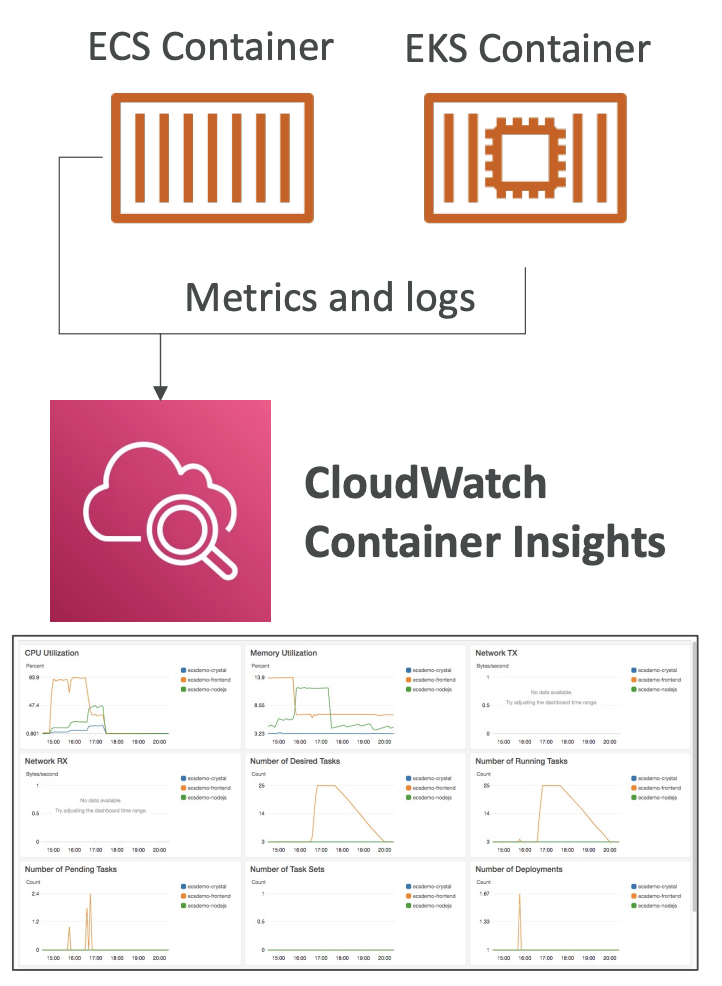
- 활용 서비스
- Amazon ECS
- Amazon EKS
- kubernetes platforms on EC2
- Fargate
- 특징
- Container버전의 CloudWatch Agent 활용 필요
CloudWatch Lambda Insight
: Lambda와 같은 서버리스 app을 위한 모니터링/트러블슈팅 솔루션특징
- 시스템 수준의 Lambda Metric을 수집/집계/요약
- Lambda Function 옆에서 실행
CloudWatch Contributor Insight
: Contributor 데이터를 표시하는 시계열 데이터를 생성하고 log를 분석하는 서비스 (VPC log, DNS log 등)Use cases : 사용량이 가장 많은 네트워크 사용자를 찾을 수 있음, DNS log에서 오류를 가장 많이 생성하는 URL을 알 수 있음
특정 패턴(ex. 사용량이 많은 네트워크 사용자순)에 대해 상위 TOP N을 추출 후 분석

CloudWatch Application Insight
: app의 잠재적인 문제와 진행중인 문제를 분리할 수 있도록 자동화된 대시보드 제공app에 문제가 있는 경우, 대시보드를 통해 잠재적인 문제를 보여줌
대시보드를 보여줄 때, 내부적으로 SageMaker가 활용됨
app 상태의 가시성을 높여줌
결론, 문제가 발생하면 대시보드에 표시하는 서비스
발견된 문제와 알림은 Amazon EventBridge와 SSM OpsCenter로 전달
CloudTail
CloudTail : AWS 계정의 거버넌스, 컴플라이언스, 감사를 실현하는 방법
특징
- 기본값으로 활성화되어 있음
- 계정에서 일어난 이벤트와 API 호출이력, SDK, CLI 활용이력 등을 얻을 수 있음 -> 로그로서 발생
- 발생한 log를 CloudWatch Logs나 Amazon S3에 Insert
- 모든 region의 log를 하나의 S3에 넣고싶을 때, trail을 생성하여 하나의 region에 적용할 수 있음

- Event 유형
- Management Events : AWS 계정 안에서 리소스에 대해 수행된 작업을 나타냄 (읽기/쓰기 이벤트 모두 나타냄)
- Data Events
- 기본 값은 로깅되지 않음 (고용량 작업)
- S3 객체 조회/수정과 같은 데이터관련 작업을 나타냄
- 읽기 이벤트/쓰기 이벤트 분리 가능
- Lambda Function 실행 작업도 해당
- CloudTrail Insights Events
- CloudTrail Insights
- API 호출 등의 리소스 작업에 대해 정상/비정상을 확인할 수 있는 기능
- 활성화하는 순간 비용 부과
- log를 분석하여 정상기준을 수립한 후, 비정상적인 패턴을 탐지하는 원리
- 부정확한 리소스 프로비저닝
- 서비스 한도 도달
- AWS IAM 액션의 폭증
- 주기적 유지보수 활동 누락

- CloudTrail Events Retention
- 기본적으로 이벤트는 CloudTrail에 90동안 보관 -> 더 오래 보관할 수도 있음 -> S3 전송 및 Athena 분석 필요 (Event 데이터 조회)
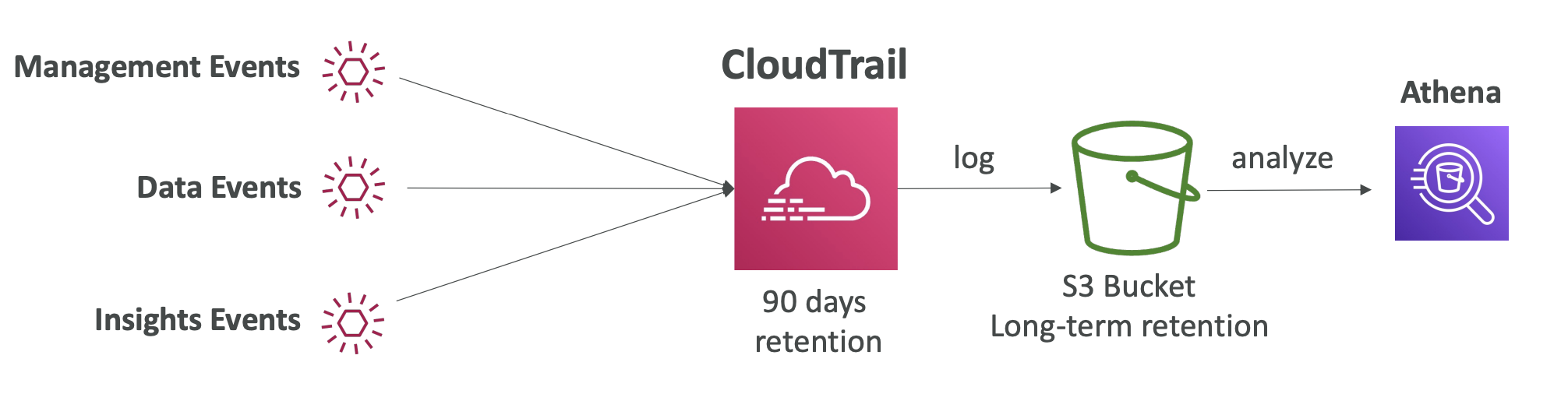
CloudTrail + EventBridge 사례
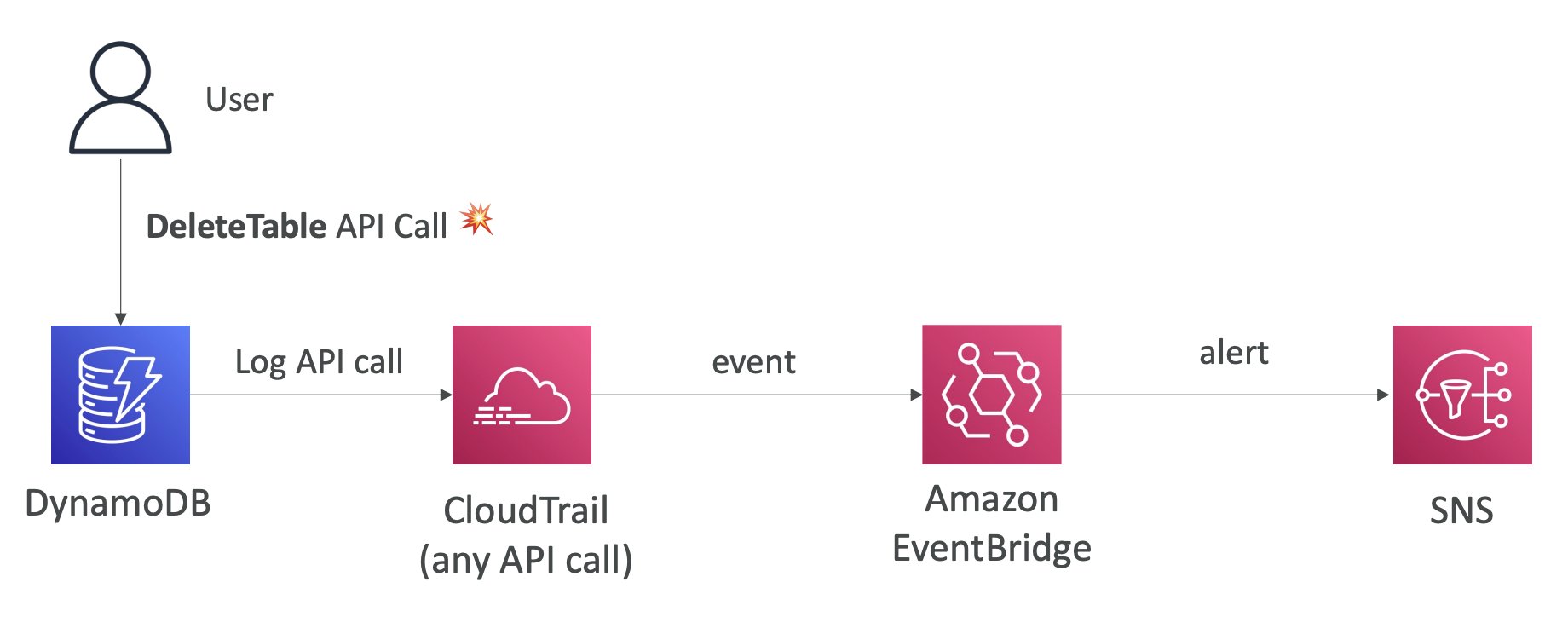
AWS Config
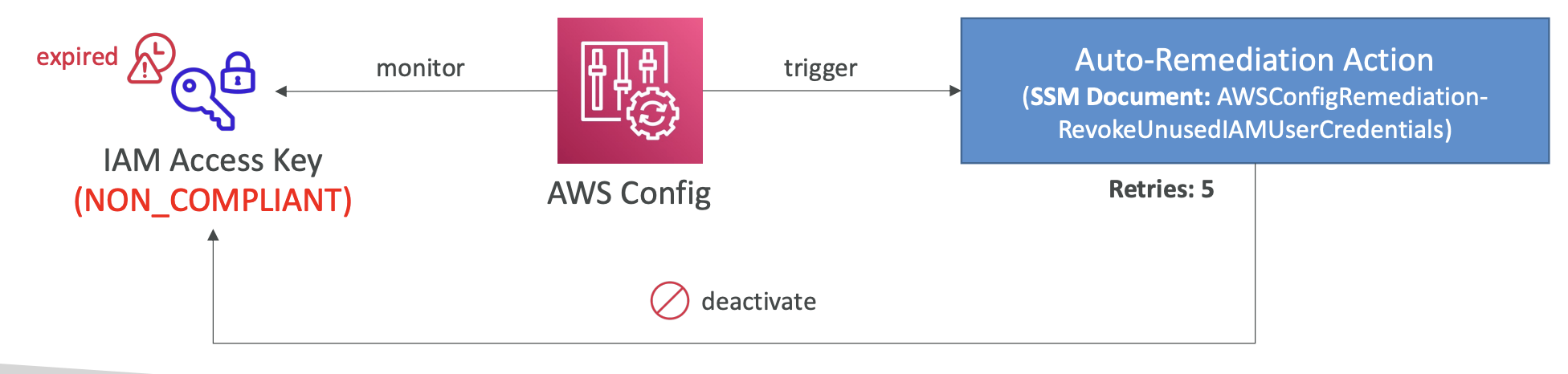
AWS Config : AWS에 대한 감사와 규정준수 여부를 기록할 수 있게하는 서비스, 시간에 따른 변화를 기록 -> 문제가 있을 경우, 인프라를 빠르게 롤백하고 문제점 파악 가능
해결할 수 있는 유형
- 보안 그룹에 제한되지 않는 SSH 접근이 있나?
- S3 Bucket에 public access가 있나?
- 시간이 지나며 설정이 변화한 ALB가 있나?
원리 : AWS Config에 등록된 rule에 대해 리소스의 변화가 생길 때마다 rule이 준수가 되고 있는지 확인함 -> 미준수 시, EventBridge, 자체 알림 기능 등으로 조치도 취할 수 있음
특징
- 규정 준수 여부에 관계없이 시간에 따라 변화가 있을 경우, SNS알림 수신 가능
- region별 구성 필요
- 데이터 중앙화를 위해 region과 계정간 데이터 통합 가능
- 모든 리소스의 구성을 S3에 저장하여 나중에 분석할 수도 있음
- 규정미준수 때마다 트리거를 걸 수도 있음
- EventBridge를 통해 트리거를 걸어 규정미준수에 대한 어떤 조치를 취할 수도 있음
7, EventBridge를 사용하지 않고도 SNS로 알림을 직접 보낼 수도 있음 - Custom Rule 작성 시, rule 미준수에 따른 action도 설정 가능


CloudWatch vs CloudTrail vs AWS Config
: ELB 예제

'개발 > AWS' 카테고리의 다른 글
| [AWS] AWS 보안 및 암호화 (1) | 2024.06.30 |
|---|---|
| [AWS] IAM 고급 (0) | 2024.06.25 |
| [AWS] AWS Database (0) | 2024.06.08 |
| [AWS] Serverless (Lambda/DynamoDB/API Gateway) (1) | 2024.06.08 |
| [AWS] AWS Container Service (0) | 2024.06.01 |