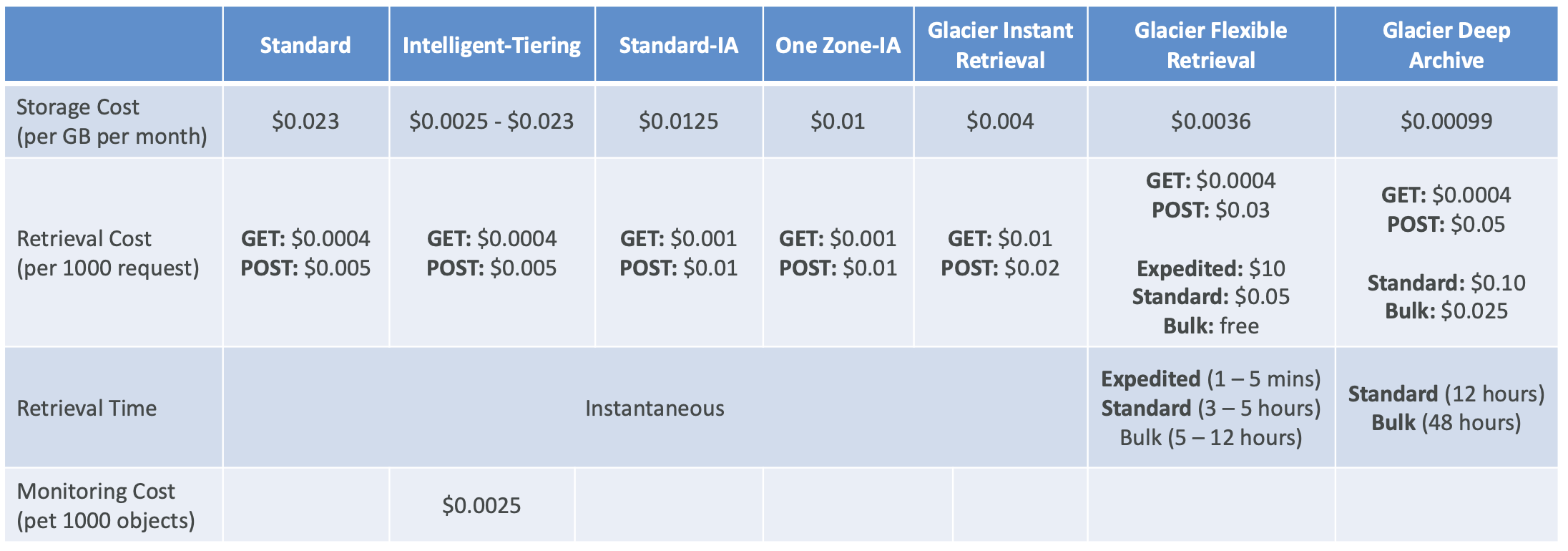
Moving between Storage Classes
- 수동으로 Object의 Storage Class를 옮길 수 있지만, LifeCycle Rules에 의해 자동으로도 옮겨질 수 있음

LifeCycle Rules
Transition Actions : 다른 Storage class로 이전하기 위한 Object 설정 (ex. 생성 60일 후에 Standard class로 이동)
Expiration Actions : 객체 삭제를 위한 Object 설정 (ex. 일정 만료기간이 지나면 Object 삭제, 특정 버전 삭제, 로그 삭제, 불완전한 객체 삭제 등)
특정 경로나 Tag로 Object를 제한할 수 있음 (tag ex. 특정 부서의 object 등)
Scenario 1

- Scenario 2

- Storage Class Analysis : 매일 S3 Bucket의 상태를 확인하여 Storage class 추천 및 통계를 담은 report를 생성
- Standard 및 Standard IA는 호환되지 않음
- report 확인까지 24~48시간 소요될 수 있음
- report를 통해 합리적인 lifecycle rules를 설정할 수 있음

Requester Pays
- As-Is : S3 Bucket 소유자가 스토리지 및 데이터 전송에 대한 비용 모두 지불
- To-Be (Requester Pays) : S3 Bucket 소유자는 스토리지 비용을, 데이터 요청자가 데이터 전송 비용을 지불 -> 데이터를 다른 사용자 계정과 공유할 때 유용 (요청자가 익명이면 안됨, AWS 인증 필요)

Event Notifications
Event : 객체 생성/삭제/복구, 복제 등과 같은 작업 (ex. S3 자체적 자동으로 image 썸네일 생성 등)
Event Notifications는 filtering이 가능 (ex. *.jpg object의 이벤트만 알림으로 받고 싶다 등)
Event Notifications의 대상은 설정 가능 (ex. SNS, SQS, Lambda Function 등)
알림은 몇 초면 전송되나 간혹 몇 분이 걸리는 경우도 있음
properties - Event Notifications 에서 설정 가능
IAM Permissions : 알림을 전송하기 위해 IAM 권한(SNS, SQS 등)이 있어야 함 -> S3 IAM Role을 사용하는 것이 아닌 Target Resource Policy에 정의함 -> 우리와 같은 사용자가 S3 Bucket에 접근할 때, S3 Bucket 정책에 기반하는 것과 비슷하다고 보면 됨 -> 보통 target이 policy 설정
ex) S3 Event Notification을 SNS 토픽에 전송하기 위해 SNS Resource Policy를 할당해야 함 (SNS 토픽에 첨부하는 IAM Policy)

- Amazon EventBridge : S3의 모든 event Notification이 EventBridge로 전송됨 -> EventBridge에 설정된 규칙을 기반으로 다른 AWS 서비스에 Event 전송 -> 직접 Event Notification를 전송하는 것보다 다양한 filtering 옵션 등과 같은 기능을 활용할 수 있음

S3 Performance
Amazon S3는 요청이 많으면 자동으로 확장됨 (지연시간 : 100~200ms)
Amazon S3는 prefix 및 초당 3500개의 PUT/COPY/POST/DELETE 요청과 5500개의 GET/HEAD 요청을 지원 -> 고성능
prefix 수에 제한이 없음 (prefix는 object의 path라 보면 됨) -> 4개의 prefix에 요청을 분산하면 초당 22000개의 GET/HEAD요청 처리 가능
최적화 방법
- Multi-Part upload : 100MB넘는 파일 권장, 5GB넘는 파일은 필수 -> upload 병렬화 -> 전송속도 증가
- Transfer Acceleration : 파일을 AWS 엣지 로케이션으로 전송, 데이터를 target region의 Bucket에 저장 -> 빠른 AWS 네트워크 활용을 통해 전송속도 증가
- Multi-Part upload와 동시 사용 가능

- Byte-Range Fetchs
- 파일의 특정 바이트 범위를 가져와 GET 요청 병렬화 -> 실패의 경우 재시도 (복원력 높음) -> 다운로드 속도 증가
- 파일의 첫 50바이트가 헤더라는 등 파일의 정보를 안다면, 파일에 대한 바이트 요청 범위를 설정할 수 있음

Select
- 파일 검색 시, 검색 후 필터링 하면 불필요하게 많은 데이터를 검색하게 됨 -> Select 기능 사용
- Select : SQL을 활용한 서버측 필터링 기능 -> 필요한 데이터만 필터링하여 조회 가능
- 데이터 검색 및 필터링에 드는 CPU 비용 절약 가능
- 적은 양의 데이터 전송에 따른 데이터 전송 속도 증가
S3 Batch Operations
S3 Batch Operations : 단일 요청으로 S3 Object에서 대량 작업 수행
Use cases
- 한 번에 많은 S3 Object의 메타데이터와 property 수정 가능
- S3 Bucket간 Object 복제 가능
- 암호화되지 않은 모든 Object를 암호화
- ACL(권한), tag 수정
- S3 Glacier에서 많은 object 복구
- Lambda 함수를 호출하여 S3 Batch Operations의 모든 객체에서 사용자 지정 작업 수행
파라미터 : 객체 list, 수행할 작업 -> 객체 list는 S3 Inventory 기능을 활용하여 가져옴
S3 Inventory : S3 Select를 활용하여 적절히 객체를 filtering하여 전달해줌

- Why? Batch Operations
- retry 관리 가능
- 진행상황 추적 및 작업완료 알림 가능
- 보고서 생성 가능
S3 Storage Lens
Storage Lens : 스토리지 이해/분석/최적화 하는 데 도움이 되는 서비스 -> 이상징후, 비용효율성 등 감지하여 전체 AWS조직을 보호 (30일 사용량 및 활용 메트릭 제공)
데이터 수집 범위
- AWS 조직
- AWS 특정 계정
- regions
- buckets
- prefixs
특징
- Custom Dashboard 제작 가능
- csv or parquet 형식으로 사용량과 메트릭에 관한 report를 S3 Bucket을 통해 받아볼 수 있음
- use cases
- 가장 빠르게 성장하거나 사용하지 않는 bucket이나 prefix 식별 (storage 관점)
- multi-part 업로드에 실패한 객체가 있는 bucket이 무엇인지? (storage 관점)
- 어떤 object를 더 저렴한 storage class로 옮길 수 있는지? (비용 관점)
- 데이터 보호 사례를 따르지 않는 bucket 식별 (데이터 보호 관점)
- Bucket이 어떤 object에 대한 소유권 설정을 하고있는지? (Bucket 소유권 관점)

- Defualt Dashboard
- 무료 및 고급 지표에 대한 요약된 인사이트와 트렌드 확인 가능
- Multi-Region, Multi-Account의 모든 데이터 확인 가능
- Amazon S3에 의해 사전 구성
- 삭제는 불가하지만 비활성화는 가능

- Metrics
- Summary Metrics : S3 Storage에 관한 insight
- StorageBytes : Storage 및 Object의 크기를 파악 (모든 버전 포함 -> 실제로 차지하는 용량, 불완전한 multi-part object도 포함)
- ObjectCount : Storage의 Object 수 파악
- Cost-Optimization Metrics : 비용에 관한 insight
- NonCurrentVersionStorageBytes, IncompleteMultipartUploadStorageBytes, etc...
- Data-Protection Metrics : 데이터 보호에 관한 insight
- VersioningEnableBucketCount : 버전관리 활성화 Bucket 수
- MFADeleteEnableBucketCount, SSEKMSEnableBucketCount, CrossRegionReplicationRuleCount, etc...
- Access-management Metrics : S3 Bucket 소유권에 관한 insight
- ObjectOwnershipBucketOwnerEnforcedBucketCount, etc...
- Event Metrics : S3 Event Notifications에 관한 insight
- EventNotificationEnabledBucketCount : Event Notification이 구성된 Bucket의 수
- Performance Metrics : Transfer Acceleration에 관한 insight
- TransferAccelerationEnabledBucketCount : Transfer Acceleration이 활성화된 Bucket의 수
- Activity Metircs
- AllRequests, GetRequests, PutRequests, ListRequests, BytesDownloaded, etc...
- Detailed Status Code Metrics : HTTP 상태 코드에 관한 insight
- 200OKStatusCount, 403ForbiddenErrorCount, 404NotFoundErrorCount, etc...
- 200OKStatusCount, 403ForbiddenErrorCount, 404NotFoundErrorCount, etc...
- 무료 metric vs 유료 metric

'개발 > AWS' 카테고리의 다른 글
| [AWS] CloudFront and Global Accelerator (0) | 2024.05.26 |
|---|---|
| [AWS] Amazon S3 (3) (0) | 2024.05.25 |
| [AWS] Amazon S3 (1) (0) | 2024.05.20 |
| [AWS] Solution Architecture (0) | 2024.05.19 |
| [AWS] Route 53 (0) | 2024.05.18 |