728x90
반응형

Amazon S3
- Use Cases
- 백업과 스토리지로 활용 (ex. 파일, 디스크, 재해복구 등)
- 아카이브 용도로 활용 -> 검색 용이
- Hybrid Cloud Storage -> 온프레미스 스토리지가 있는 상태에서 클라우드로 서비스를 확장
- application, file, image 등 미디어를 호스팅할 수 있음
- 다량의 데이터를 저장하고 빅데이터 분석 수행
- 정적 웹사이트 호스팅
- S3 Buckets
- 파일(=객체) 저장 용도
- 상위 레벨 디렉토리로 표시
- 계정 안에 생성되고, 모든 region의 고유한 이름이 있어야 함 (전역 서비스로 착각x -> 특정 region 국한 서비스)
- region 수준 정의
- Name convention
- 대문자(x)
- 밑줄(x)
- 길이 3~63
- ip(x)
- 소문자나 숫자로 시작
- 접두사 제한 (ex. xn--, -s3alias 등)
- 문자, 숫자, 하이픈 사용
- 인터넷망에서 bucket내부 object에 접근하기 위해서 public 설정 필요 (default는 amazon credential을 활용하여 private하게 접근)
- S3 Objects
- body는 본문의 내용 (file 등)
- Object당 최대 크기는 5TB
- 크기가 5GB 이상이라면, multi-part로 업로드하여 여러 부분으로 나누어 업로드
- key-value 형태의 메타데이터 존재 (object에 관한 부가정보)
- tags (유니코드 최대 10개 key-value쌍), 보안과 lifecycle에 유용
- Version ID를 갖기도 함
- S3 Object key
- 모든 Object는 key를 가짐
- key는 파일(object)의 전체 경로
- s3://my-bucket/my_file.txt -> key : my_file.txt, 상위디렉토리 : s3://my-bucket/
- s3://my-bucket/my_folder1/another_folder/my_file.txt -> key : my_folder1/another_folder/my_file.txt
- key = 접두사 + file(object) name
- 디렉토리의 개념은 없음 (디렉토리처럼 보이지만, 핵심은 key)
Security
- 사용자 기반
- IAM 정책 : 특정 사용자(동일 계정의 IAM User(?))에게 특정 S3 API 호출 허용
- IAM Role : 특정 EC2 인스턴스에게 특정 S3 API 호출 허용
- 리소스 기반
- S3 Bucket 정책 : S3 console에서 할당 가능, 특정 사용자에게 bucket 접근을 허용 (교차계정, 다른 계정의 IAM User)
- Object ACL (Object Access Control List) : 가장 세밀한 권한
- Bucket ACL (Bucket Access Control List) : Object 보다 덜 세밀한 권한
- 암호화
- 암호키를 사용하여 S3 object 암호화
=> S3 Object에 접근할 수 있는 경우는 위에서 언급된 사용자 기반 IAM 권한을 얻거나, 리소스 기반 정책이 허용할 경우
- S3 Bucket Policies
- JSON기반의 정책
- Resource : 정책이 적용되는 bucket과 object 명시
- Effect : Allow/Deny 선택
- Action : 정책에서 명시할 작업(API)
- Principal : 해당 정책을 적용할 대상(사용자)

- Public Access : S3 Bucket Policy

- Cross-Account Access : S3 Bucket Policy

- User Access : IAM permissions

- EC2 Access : IAM Roles

- Block Public Access
- 기업 데이터 유출을 방지하기 위한 추가 보안 계층
- Bucket 생성 시, 설정
- Bucket Policy를 통해 Public Access를 허용하더라도 해당 설정이 활성화되어 있으면, public 접근 불가
- 잘못된 Bucket Policy 설정으로 인한 유출사고 방지
- public Bucket Policy 설정 시에만 비활성화해야 함
Website
- S3를 활용하여 정적 웹사이트 hosting 가능
- S3 Bucket 설정 중, properties - static website hosting 설정에서 활성화 필요
- index.html 파일 업로드 필요
- S3 Bucket에 대한 권한 허용 필요
Versioning
- S3에서 File의 버전 관리 가능
- Bucket 설정에서 활성화 필요 (properties - bucket versioning)
- 동일한 key를 upload하고 파일을 덮어쓰는 경우 버전 2, 버전 3... 생성
- 의도치 않은 File 삭제 방지 -> versioning이 활성화되어 있는 상태에서 파일을 삭제할 경우, 삭제마커가 추가되어 삭제가 versioning됨 -> 복구 가능
- 파일 버전을 삭제한 경우, 파일이 삭제되는 것이 아닌 해당 버전만 삭제
- 이전 버전으로 roll-back 가능
- 유의1 : 버전 관리가 적용되지 않은 모든 파일은 null 버전을 갖게됨
- 유의2 : 버전 관리를 중단해도 이전 버전을 삭제하진 않음

Replication
- management - Replication rules 에서 복제설정
- source bucket, destination bucket 둘다 Versioning 활성화 필요
- S3에 알맞는 IAM Role 할당(Bucket에 대한 읽기/쓰기 권한) 필요
- 복제는 비동기식으로 진행 (background 진행)
- 서로 다른 AWS 계정간 사용 가능
- 복제를 활성화한 후, 새로 추가되는 object만 복제 대상이 됨
- 기존 object 복제를 위해 S3 Batch 복제를 활용해야 함 (기존 object, 복제실패 object 복제)
- 삭제작업 복제를 위해 삭제마커(version)도 복제하면 됨 (설정에서 가능, Delete marker replication 활성화)
- version삭제는 복제 불가
- chaining 복제 불가 (bucket 1 -> bucket 2 -> bucket 3 (x))
- CRR (교차 리전 복제)
- source bucket과 destination bucket의 region이 다름
- region간 지연시간 감소를 위해 사용
- AWS 계정간 복제를 위해 사용
- SRR (같은 리전 복제)
- source bucket과 destination bucket의 region이 동일
- 다수 S3 Bucket간 통합
- 개발환경과 운영환경 실시간 동기화
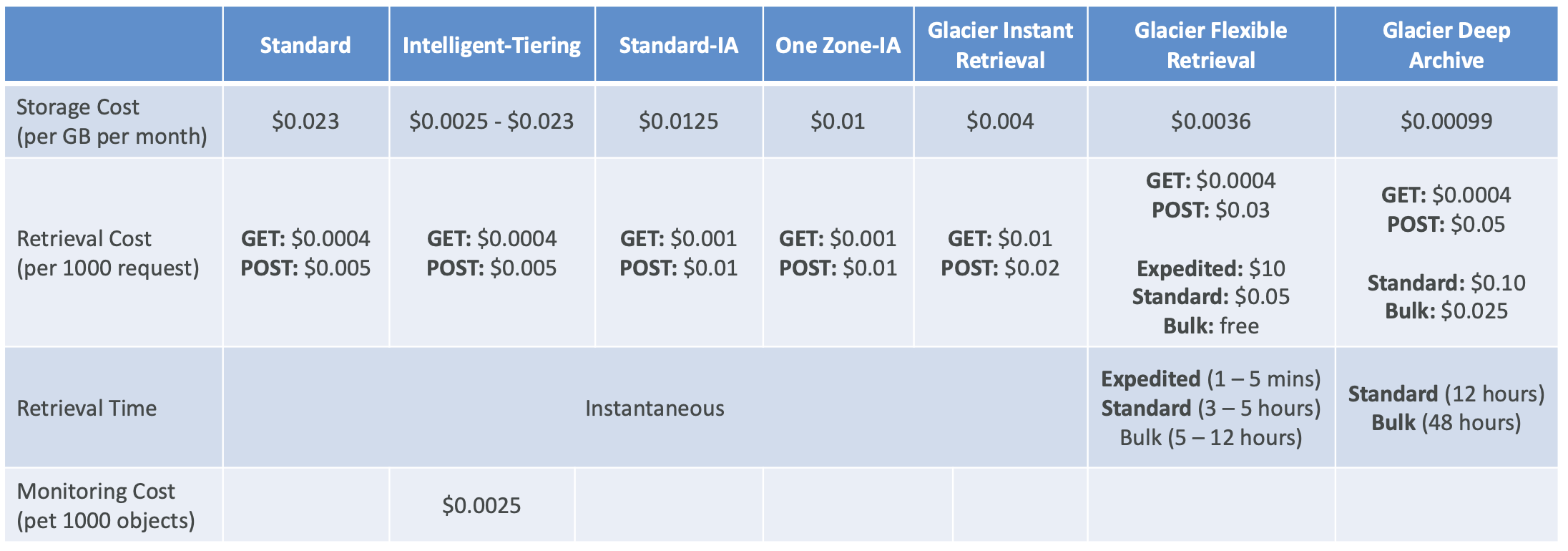
Storage Classes
객체 생성 시, class 선택가능 (properties - storage class)
수동으로 수정도 가능
S3 Lifecyle 설정을 통해 기간에 따른 class간 객체이동 자동화도 가능 (management - lifecycle rules)
Durability (내구성) : S3로 인해 객체가 손실되는 횟수, 모든 class에서 동일
Availability (가용성) : 서비스가 얼마나 용이하게 제공되는지, class에 따라 다름 (ex. 99.99% : 1년에 53분 동안 서비스 사용 불가)
Classes
Standard - General Purpose
- 가용성 : 99.99%
- 자주 access하는 데이터를 위해 사용
- 지연시간이 짧고 처리량이 높음
- 두 개의 기능장애를 동시에 버틸 수 있음
- use cases : 빅데이터 분석, mobile/game application, 배포 등
Standard - Infrequent Access (IA)
- 가용성 : 99.9%
- 자주 access하진 않지만, 빠른 접근이 필요할 때 사용
- General Purpose보다 비용이 저렴 (검색 비용 발생)
- use cases : 재해복구, 백업 등
One Zone - Infrequent Access
- 가용성 : 99.5%
- 단일 AZ 내에서 높은 내구성 (99.999999999%)
- AZ가 파괴된 경우, 데이터를 잃게 됨
- use cases : 온프레미스 데이터 2차 백업, 재생성 가능한 데이터 저장 등
Glacier
Glacier = cold storage, 아키이빙과 백업을 위한 저비용 객체 스토리지
스토리지 및 검색 비용 부과
1) Instant Retrieval- 밀리초 단위 검색
- 분기에 한번 access하는 데이터에 적합
- 최소 보관 기간은 90일
2) Flexible Retrieval
- Expedited : 1~5분 내에 데이터 수집 가능
- Standard : 3~5시간 내에 데이터 수집 가능
- Bulk : 5~12시간 내에 데이터 수집 가능 (free)
- 최소 보관 기간은 90일
3) Deep Archive
- Standard : 데이터 수집까지 12시간 소요
- Bulk : 데이터 수집까지 48시간 소요
- 비용이 가장 저렴
- 최소 보관 기간은 180일
- 장기간 저장에 적합
Intelligent Tiering
- 사용 패턴에 따라 access tier간 객체 이동
- 월별 모니터링 비용과 객체 이동(tiering) 비용 발생, 검색 비용은 없음
- FrequentAccess : default
- InfrequentAccess : 30일 동안 access하지 않는 object전용
- ArchiveInstantAccess : 90일 동안 access하지 않는 object전용
- ArchiveAccess : 90일부터 700일 이상 access하지 않는 object전용, 객체 자동이동은 optional
- DeepArchiveAccess : 180일부터 700일 이상 access하지 않는 object전용, 객체 자동이동은 optional
- Storage classes 성능 비교

- Storage classes Price
반응형
'개발 > AWS' 카테고리의 다른 글
| [AWS] Amazon S3 (3) (0) | 2024.05.25 |
|---|---|
| [AWS] Amazon S3 (2) (0) | 2024.05.22 |
| [AWS] Solution Architecture (0) | 2024.05.19 |
| [AWS] Route 53 (0) | 2024.05.18 |
| [AWS] Amazon RDS/Aurora/ElastiCache (1) | 2024.05.10 |