
1. 배경
지난 23년 12월 말에 파트 내에서 개발한 UI화면의 조회과정에서 부하가 발생하였습니다.
이에 따라 인프라팀으로부터 쿼리 튜닝 요청이 왔습니다.
먼저 저는 문제의 쿼리를 실행시키는 화면을 먼저 알아봤습니다.
해당 화면은 조회를 위해 여러 키 값을 입력할 수 있는 구조로 되어 있는데,
이 중, 필수 파라미터는 최대 7일까지 입력할 수 있는 기간 데이터와
최대 1개까지 입력할 수 있는 통신국사였습니다.
해당 화면의 조회쿼리 성능이 나쁘다는 전제가 있어서 필수 파라미터만 키 값으로 넣되,
조회 기간은 1일로 설정하여 조회를 시도해봤습니다.
그 결과, 화면은 바로 멈춰버리고...
모니터링 툴인 파로스상으로 확인해봤을 때, 해당 트랜잭션의 실행은 15~20분정도 지나서야 종료가 되었습니다.
기간을 1일로 잡아도 이정도의 성능을 보이는 것을 보니까... 생각보다 심각하구나라는 걸 인지하게 되었어요.
2. 튜닝 과정
먼저 저는 문제의 쿼리를 파악해봤습니다.
아래 쿼리는 파로스상 가장 오랜시간의 지연을 가진 쿼리입니다.
SELECT count(*) totalCount
FROM (
SELECT crt.*
FROM PNA_CIRCUITATHN_RQT_TXN crt,
TB_OFFICE office,
PNA_ORTR_TELNO_TXN tel,
WHERE
crt.OBDNG_ID=office.OFFICESCODE(+)
AND crt.ORDR_TRT_NO=tel.ORDR_TRT_NO(+)
AND tel.CHG_BEFAFT_TYPE_CD(+) = '2'
AND tel.TEL_NO_TYPE_CD(+) = '1'
AND crt.OBDNG_ID IN ('R02471')
AND crt.RQT_DT BETWEEN TO_DATE('20240104' || '000000', 'YYYYMMDDHH24MISS')
AND TO_DATE('20240104' || '235959', 'YYYYMMDDHH24MISS')
);위 쿼리에서 조건 키값으로 입력한 통신국사의 코드는 OBDNG_ID이고, 기간 데이터는 RQT_DT컬럼의 데이터로 입력됩니다.
지연의 원인을 파악하기 위해 실행계획을 확인해봤습니다.
Plan hash value: 3635163560
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 39 | | |
| 2 | NESTED LOOPS OUTER | | 1 | 39 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| PNA_CIRCUITATHN_RQT_TXN | 1 | 25 | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | PNA_CIRCUITATHN_RQT_TXN_IX_02 | 1 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PNA_ORTR_TELNO_TXN_PK | 1 | 14 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$ABC8FBB0
3 - SEL$ABC8FBB0 / CRT@SEL$2
4 - SEL$ABC8FBB0 / CRT@SEL$2
5 - SEL$ABC8FBB0 / TEL@SEL$2
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("CRT"."RQT_DT">=TO_DATE(' 2024-01-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"CRT"."OBDNG_ID"='R02471' AND "CRT"."RQT_DT"<=TO_DATE(' 2024-01-04 23:59:59', 'syyyy-mm-dd
hh24:mi:ss'))
filter("CRT"."OBDNG_ID"='R02471')
5 - access("CRT"."ORDR_TRT_NO"="TEL"."ORDR_TRT_NO"(+) AND "TEL"."TEL_NO_TYPE_CD"(+)='1' AND
"TEL"."CHG_BEFAFT_TYPE_CD"(+)='2')
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - (#keys=0) COUNT(*)[22]
2 - (#keys=0)
3 - "CRT"."ORDR_TRT_NO"[VARCHAR2,11]
4 - "CRT".ROWID[ROWID,10]그런데... 실행계획상 성능이 나쁘진 않았습니다.
해당 실행계획을 가진 쿼리가 15분 이상을 지연시킨 쿼리라고 하니... 이해가 되질 않았어요.
모니터링 툴이었던 파로스가 쿼리 실행시간을 제대로 못 잡은건지도 의심이 들었습니다.
그래서 실제 실행시켰던 쿼리의 실행계획이 궁금했고, 인프라팀에 문의했습니다.
실행계획 성능과 실제 지연시간과 차이가 발생한 이유로 해당 쿼리에 바인드 변수가 사용되었기 때문일 수도 있다는 답변을 받았습니다.
바인드 변수 쿼리
바인드 변수 쿼리는 변수가 사용된 쿼리입니다. 아래와 같은 형태로 사용됩니다.SELECT * FROM tb_test WHERE id = :id;
위 쿼리에서 조건절의 :id로 표현된 부분에 여러 id값이 입력되는 바인드 변수입니다.
위 쿼리에서처럼 바인드 변수 쿼리로 실행되지 않고, 아래처럼 상수 형태로 입력되어 실행된다면
쿼리는 한번 사용된 실행계획을 재사용하는 것이 아닌 새로 실행계획을 수립하는 Hard parsing이 진행되어 성능상 비효율이 발생합니다.
SELECT * FROM tb_test WHERE id = 1;
SELECT * FROM tb_test WHERE id = 2;
SELECT * FROM tb_test WHERE id = 3;
SELECT * FROM tb_test WHERE id = 4;
SELECT * FROM tb_test WHERE id = 5;그렇기 때문에 성능상 이점을 위해서는 바인드변수 쿼리를 사용해야 합니다.
바인드변수 쿼리를 사용하게 되면, 바인드 변수의 값만 바꿔서 쿼리를 실행시킬 때, 해당 쿼리에 맞는 이미 실행되었던 실행계획을 재사용하여 실행시키는 Soft parsing이 진행되기 때문에 더욱 빠르게 실행시킬 수 있습니다.
하지만 맹점이 있었습니다.
바인드 변수에 해당하는 조건의 값을 예측하기가 어려워 잘못된 실행계획을 수립할 수도 있습니다.
본 글에서 언급한 쿼리의 비효율도 해당 맹점으로 인해 발생했습니다.
그리고 아래는 바인드 변수 쿼리로 수립된 실행계획입니다.
Plan hash value: 3105806070
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 5232 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 39 | | |
|* 2 | FILTER | | | | | |
| 3 | NESTED LOOPS OUTER | | 75 | 2925 | 5232 (1)| 00:00:01 |
|* 4 | TABLE ACCESS BY INDEX ROWID| PNA_CIRCUITATHN_RQT_TXN | 67 | 1675 | 5231 (1)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | PNA_CIRCUITATHN_RQT_TXN_IX_03 | 26649 | | 33 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | PNA_ORTR_TELNO_TXN_PK | 1 | 14 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$ABC8FBB0
4 - SEL$ABC8FBB0 / CRT@SEL$2
5 - SEL$ABC8FBB0 / CRT@SEL$2
6 - SEL$ABC8FBB0 / TEL@SEL$2
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:3||'235959','YYYYMMDDHH24MISS')>=TO_DATE(:2||'000000','YYYYMMDDHH24MISS'))
4 - filter("CRT"."RQT_DT">=TO_DATE(:2||'000000','YYYYMMDDHH24MISS') AND
"CRT"."RQT_DT"<=TO_DATE(:3||'235959','YYYYMMDDHH24MISS'))
5 - access("CRT"."OBDNG_ID"=:1)
6 - access("CRT"."ORDR_TRT_NO"="TEL"."ORDR_TRT_NO"(+) AND "TEL"."TEL_NO_TYPE_CD"(+)='1' AND
"TEL"."CHG_BEFAFT_TYPE_CD"(+)='2')
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - (#keys=0) COUNT(*)[22]
3 - (#keys=0)
4 - "CRT"."ORDR_TRT_NO"[VARCHAR2,11]
5 - "CRT".ROWID[ROWID,10]인덱스 스캔
위 쿼리의 비효율은 잘못된 인덱스를 스캔하는 실행계획을 수립했기 때문에 발생하였습니다.
실행계획상으로 볼 수 있다시피 상수쿼리는 PNA_CIRCUITATHN_RQT_TXN_IX_02 인덱스를 스캔한 반면에,
바인드변수 쿼리는 PNA_CIRCUITATHN_RQT_TXN_IX_03 인덱스를 스캔했어요. 3번 인덱스를 스캔한 시점에서 쿼리 실행에 많은 비용이 발생하게 됩니다.
튜닝 대상의 쿼리에는 여러개의 인덱스가 생성되어 있는데,
그 중 대표적으로 봐야할 두 개의 인덱스가 있습니다.
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_02 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(RQT_DT, OBDNG_ID, RQT_TRT_RESLT_SBST)
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_03 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(OBDNG_ID, ORDR_TYPE_ID, ORDR_TRT_TYPE_SEQ)쿼리에서 확인할 수 있는 것처럼 조건절에는 OBDNG_ID컬럼과 RQT_DT컬럼이 있고,
해당 컬럼이 모두 있는 2번 인덱스를 스캔해야 효율적인 쿼리 실행이 가능합니다.
하지만 바인드변수 쿼리는 OBDNG_ID컬럼만 있는 3번 인덱스를 스캔했는데요.
이러한 잘못된 스캔의 원인으로 바인드변수 쿼리 실행시에는 변수에 어떤 값이 입력될지 몰라서 Optimizer가 조회할 데이터의 양을 예측하지 못하는데 있다고 추측됩니다.OBDNG_ID컬럼의 경우, in절이라서 변수의 갯수로 어느정도 예측을 할 수 있지만,RQT_DT컬럼의 경우는 예측이 안되어 OBDNG_ID가 선행컬럼으로 있는 3번 인덱스를 스캔하게 된 것이죠.
해결방안
힌트 추가
첫번째 개선방안은 인덱스 힌트를 추가하여 특정 인덱스를 강제로 스캔하는 방안이었습니다.
아래는 인덱스 힌트가 추가된 쿼리입니다.
SELECT count(*) totalCount
FROM (
SELECT /*+ index (crt PNA_CIRCUITATHN_RQT_TXN_IX_02) */
crt.*
FROM PNA_CIRCUITATHN_RQT_TXN crt,
TB_OFFICE office,
PNA_ORTR_TELNO_TXN tel,
WHERE
crt.OBDNG_ID=office.OFFICESCODE(+)
AND crt.ORDR_TRT_NO=tel.ORDR_TRT_NO(+)
AND tel.CHG_BEFAFT_TYPE_CD(+) = '2'
AND tel.TEL_NO_TYPE_CD(+) = '1'
AND crt.OBDNG_ID IN ('R02471')
AND crt.RQT_DT BETWEEN TO_DATE('20240104' || '000000', 'YYYYMMDDHH24MISS')
AND TO_DATE('20240104' || '235959', 'YYYYMMDDHH24MISS')
);힌트는 아래와 같은 형태로 추가되어 쿼리 실행시에 특정 인덱스를 고정적으로 스캔할 수 있도록 강제할 수 있습니다./*+ index (crt PNA_CIRCUITATHN_RQT_TXN_IX_02) */
위 인덱스 힌트는 사전에 검증된 성능의 2번 인덱스를 스캔하기 위한 구문입니다.
하지만 힌트가 추가되었을 때의 문제는 바인드 변수에 값이 랜덤하게 입력되는데,
선행컬럼이 OBDNG_ID로 구성되어 있는 인덱스를 스캔하는 것이 더 성능이 좋은 케이스도 분명 존재한다는 것입니다. 3번 인덱스처럼 말이죠.
하지만 3번 인덱스에는 RQT_DT컬럼이 없죠.
인덱스 추가
위에서 언급한 것처럼 바인드 변수에 입력되는 값에 따라 OBDNG_ID 선행컬럼의 인덱스를 스캔하는 것이 더 효율적일 수도 있습니다.
이러한 경우를 대비해서 아래 6번 인덱스를 추가하기로 결정했습니다.
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_06 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(OBDNG_ID, RQT_DT, RQT_TRT_RESLT_SBST)기존 검증된 성능의 2번 인덱스와 동일한 컬럼 구성의 6번 인덱스를 생성하되, 선행컬럼을 RQT_DT에서 OBDNG_ID로 바꾸어OBDNG_ID 선행컬럼의 인덱스를 스캔하는 것으로 Optimizer가 실행계획을 수립해도 RQT_DT 컬럼도 인덱스로 같이 스캔할 수 있게끔 할 수 있습니다.
결과
아래는 인덱스 적용 후의 쿼리 실행계획입니다.
Plan hash value: 1313069470
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 127 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 39 | | |
|* 2 | FILTER | | | | | |
| 3 | NESTED LOOPS OUTER | | 75 | 2925 | 127 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID| PNA_CIRCUITATHN_RQT_TXN | 67 | 1675 | 126 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | PNA_CIRCUITATHN_RQT_TXN_IX_06 | 120 | | 1 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | PNA_ORTR_TELNO_TXN_PK | 1 | 14 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$ABC8FBB0
4 - SEL$ABC8FBB0 / CRT@SEL$2
5 - SEL$ABC8FBB0 / CRT@SEL$2
6 - SEL$ABC8FBB0 / TEL@SEL$2
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_DATE(:3||'235959','YYYYMMDDHH24MISS')>=TO_DATE(:2||'000000','YYYYMMDDHH24MISS'))
5 - access("CRT"."OBDNG_ID"=:1 AND "CRT"."RQT_DT">=TO_DATE(:2||'000000','YYYYMMDDHH24MISS') AND
"CRT"."RQT_DT"<=TO_DATE(:3||'235959','YYYYMMDDHH24MISS'))
6 - access("CRT"."ORDR_TRT_NO"="TEL"."ORDR_TRT_NO"(+) AND "TEL"."TEL_NO_TYPE_CD"(+)='1' AND
"TEL"."CHG_BEFAFT_TYPE_CD"(+)='2')
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - (#keys=0) COUNT(*)[22]
3 - (#keys=0)
4 - "CRT"."ORDR_TRT_NO"[VARCHAR2,11]
5 - "CRT".ROWID[ROWID,10]3번 인덱스가 아닌 6번 인덱스를 스캔하는 것을 실행계획상 확인하였고,
UI에서 조회시에도 기존에는 기간을 하루로 설정하여 조회해도 15분 이상이 소요되었는데,
인덱스가 추가 반영된 이후에는 기간을 최대 7일까지 설정해도 조회시간이 최대 3초 이내로 마무리된 것까지 확인하여
성능이 크게 개선된 것을 확인하였습니다.
Oracle 쿼리 처리 과정
https://docs.oracle.com/database/121/TGSQL/tgsql_sqlproc.htm#TGSQL175
Oracle 공식 document에 작성되어 있는 가이드를 참고하여 Oracle 쿼리의 처리 과정과 관련 개념에 대해서 간략히 짚고 넘어가겠습니다.
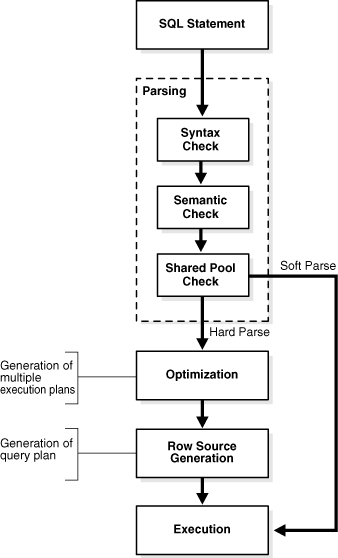
위 사진은 Oracle SQL 처리순서를 표현한 도식입니다.
Application에 의해 SQL이 실행되면 DB서버에서는 PGA(Program Global Area) 내부에 private SQL area를 생성하고, 이를 가리키는 포인터인 Cursor를 생성하여 실행된 SQL을 파싱할 준비를 합니다.
- PGA (Program Global Area) : 각각의 Application이 독자적으로 사용하는 Oracle 메모리 영역
- private SQL area : 실행된 SQL과 처리를 위한 정보가 담기는 PGA 내부의 메모리 영역, 처리를 위한 정보로 바인드 변수 값과 쿼리 실행 상태 등의 정보가 있음.
Syntax Check
실행된 SQL이 문법상 유효한지 확인하는 과정입니다.
예를들어, 아래 쿼리는 해당 과정에서 오류로 반환될 것입니다. (FORM을 FROM으로 수정 필요)
SELECT * FORM employees;
Semantic Check
실행된 SQL이 문법상 유효하다면, 이제 의미상으로 유효한지 본 과정에서 확인하게 됩니다.
예를들어, 아래 쿼리가 실행된다고 가정해봅시다.
SELECT * FROM nonexistent_table;
위에서 실행된 쿼리의 테이블 nonexistent_table이 실제로 존재하지 않는 테이블이라고 가정했을 때,
위 실행쿼리는 의미상 유효하지 않으므로 본 과정에서 에러를 반환하게 됩니다.
Shared Pool Check
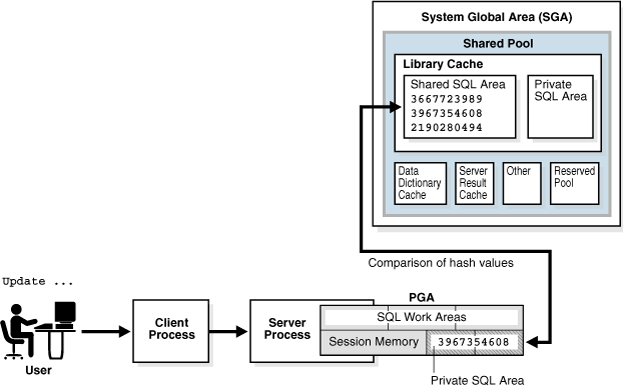
쿼리 성능에 크게 영향을 미치는 과정입니다.
unique한 각각의 SQL에는 해시값의 SQL_ID가 있습니다. 동일한 SQL은 동일한 SQL_ID를 갖죠.
본 과정에서는 실행된 쿼리의 SQL_ID가 Shared SQL Area에 존재하는지 확인하게 되고,
동일한 SQL_ID가 존재하지 않는다면 Hard Parsing을 진행하게 됩니다.
- Shared SQL Area : 각 PGA (Program Global Area)에서 실행된 SQL과 실행계획 등과 같은 정보를 공유하는 메모리 공간
동일한 SQL_ID가 존재한다면, 추가적인 semantic check와 environment check를 거칩니다.
실행된 SQL이 동일한 SQL_ID를 가진 SQL과 문법상 같은 SQL을 가졌다고 하더라도 의미상/환경상 차이를 보일 수 있기 때문이죠.
그리고 위의 추가적인 검증절차를 통과하지 못해도 Hard Parsing을 진행하게 됩니다.
모든 검증절차를 통과한 SQL만이 Soft Parsing을 진행할 수 있게 됩니다.
- Soft Parsing : 기존 실행되었던 실행계획을 재사용하여 쿼리를 실행
- Hard Parsing : Optimization 단계를 거쳐 새로운 실행계획을 수립하여 쿼리를 실행
SQL Optimization
본 과정에서 새로운 실행계획이 수립됩니다.
SQL engine이 바이너리 형태의 초기 실행계획을 row source generator에게 전달하면,row source generator는 전달받은 바이너리 형태의 초기 실행계획을 row source tree형태로 생성하여
우리가 흔히 알고 있는 실행계획을 생성해줍니다.
그리고 SQL engine이 다시 생성된 실행계획을 실행시키는 것으로 SQL의 처리가 완료됩니다.
위에서 참고한 Oracle 가이드에는 실제로 최적화가 어떻게 이루어져 최적의 실행계획을 추출하는지에 대한 내용이 없어서...
관련 내용은 추가적인 서핑이 필요합니다.
다음 글에서는 SQL engine이 어떤 정보를 기반으로 어떻게 최적화를 진행하는지, 어떻게 쿼리를 작성하고 튜닝하는 것이 바람직한지 알아보겠습니다.
'개발 > DB' 카테고리의 다른 글
| 쿼리튜닝기 (1) (1) | 2023.07.27 |
|---|---|
| [SQLD] 필기시험 대비 나만의 요약 정리 (3) | 2023.06.06 |