728x90
반응형

Database를 선택하는 방법
- 읽기량/쓰기량 고려
- 데이터 처리량 고려
- 데이터 저장량
- 데이터 저장 기간
- 평균 객체 크기
- 객체에 접근하는 방법
- 확장이 가능한지?
- 데이터 공급원은 어디인지?
- 데이터 내구성이 있는지?
- 지연시간에 관한 요구사항이 있는지?
- 동시 사용자에 관한 요구사항이 있는지?
- 데이터 모델이 뭔지?
- 쿼리 방법이 뭔지?
- 데이터 join이 많은지?
- 정규화? 반정규화?
- 유연성이 있는지?
- reporting이 필요한지?
- 관계형? NoSQL?
- 라이선스 비용이 있는지?
- Database Types
- RDBMS : RDS, Aurora
- NoSQL : DynamoDB(JSON), ElastiCache(key-value), Neptune(Graphs), MongoDB(DocumentDB), Apache Cassandra(Keyspaces)
- Object Store : S3, Glacier
- Data Warehouse : Redshift(OLAP), Athena. EMR
- Search : OpenSearch(JSON)
- Graphs : Amazon Neptune
- Ledger : Amazon Quantum Ledger Database
- Time series : Amazon Timestream
RDS
- PostgreSQL, MySQL, Oracle, SQL Server, MariaDB 지원
- RDS 인스턴스 크기 및 EBS Volume Type/Size를 사전 지정해야 함
- 스토리지에 대한 Auto-scaling 기능이 있음
- 읽기 전용 복제본 지원
- 고가용성 목적으로 Standby DB를 다중 AZ에 배치할 수 있음 (해당 DB엔 쿼리 실행 불가)
- IAM을 통해 사용자 보안조치 가능 (사용자이름/비밀번호, 일부 사용자에게 IAM 인증 부여)
- Security Groups을 통해 네트워크 보안
- KMS를 통해 데이터 저장 보안
- SSL을 통해 전송 데이터 보안
- 최대 35일의 자동 백업 옵션 -> 해당 기간 내 새로운 DB로 복구 가능
- 장기 보존 백업이 필요한 경우 DB Snapshot 이용 가능
- 패치 작업 등을 위해 downtime이 있을 수 있음
- RDS Proxy를 추가하여 RDS에 IAM 인증 추가
- Secrets Manager와 통합하여 DB 자격증명 관리
- RDS 인스턴스에 접근을 위한 사용자 지정옵션 있음 (Oracle / SQL Server)
- 관계형 DB 및 OLTP를 저장하는데 활용
Aurora
- PostgreSQL, MySQL 지원
- 스토리지와 컴퓨팅이 구분됨
- 기본 설정으로 3개 AZ에 6개의 인스턴스로 나누어 데이터를 저장함 -> 고가용성
- 자동 자가복구 과정이 있음
- 스토리지에 대한 Auto-scaling 기능이 있음 (읽기 전용 복제본도 가능)
- DB Cluster가 구축되어 있기 때문에 어느 인스턴스에 접근하여 읽고 쓸지를 결정하기 위해 별도 endpoint가 필요 (writer endpoint, reader endpoint)
- RDS와 동일한 Security/monitoring/maintenance 기능이 있음 -> 같은 엔진 활용
- Aurora를 위한 백업 및 복구 기능이 있음
- Aurora Serverless -> 예측할 수 없는 간헐적인 workload가 있을 때 용량을 별도로 계획하지 않아도 되기 때문에 유용함
- Global DB를 위해 Aurora Global이 사용됨 -> 16개의 read전용 인스턴스가 각 region에 배포됨 -> 1초 미만의 실시간 스토리지 복제 -> 특정 region에 문제가 생겼을 때, 다른 region의 DB를 주요 region으로 승격시킬 수 있음
- 머신러닝을 위한 Aurora Machine Learning 모듈이 있음
- 테스트 DB 및 스테이징 DB를 위해 Aurora cloning 기능이 있음, snapshot을 복구하는 것보다 빠름 -> 새로운 cluster 구축
- RDS보다 비용이 더 비싸지만, 더 유연성있고, 덜 관리하고, 더 좋은 성능, 더 많은 기능을 원하면 사용
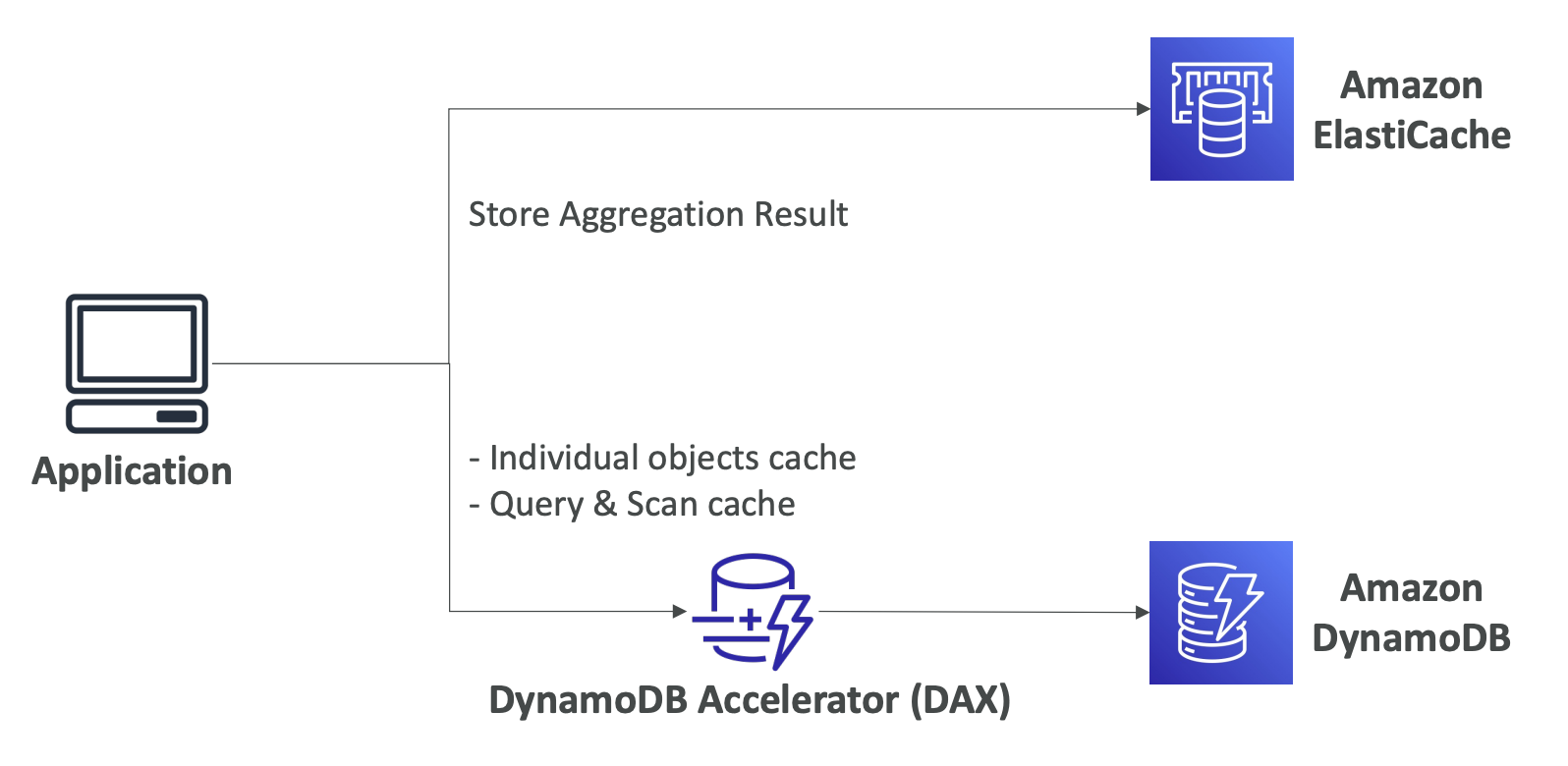
ElastiCache
- Redis / Memcached 두 종류
- 캐싱작업에 활용
- in-memory store
- 1ms 미만의 읽기 성능을 제공
- 캐싱을 위한 EC2 인스턴스가 프로비저닝 되어야 함
- Redis에서는 Clustering 기능 제공 및 Multi-AZ, Sharding을 통한 읽기 전용 복제본 제공
- IAM을 통한 접근 보안, Security Groups(네트워크 수준의 접근), KMS(데이터 저장), Redis Auth가 있음
- RDS처럼 백업 및 Snapshot, point in time restore 기능 제공
- app code가 ElastiCache를 사용하도록 수정 필요
- Use Cases : key-value store, 빈번한 읽기, DB 쿼리 캐싱, 세션 데이터 저장 등
- SQL 사용 불가
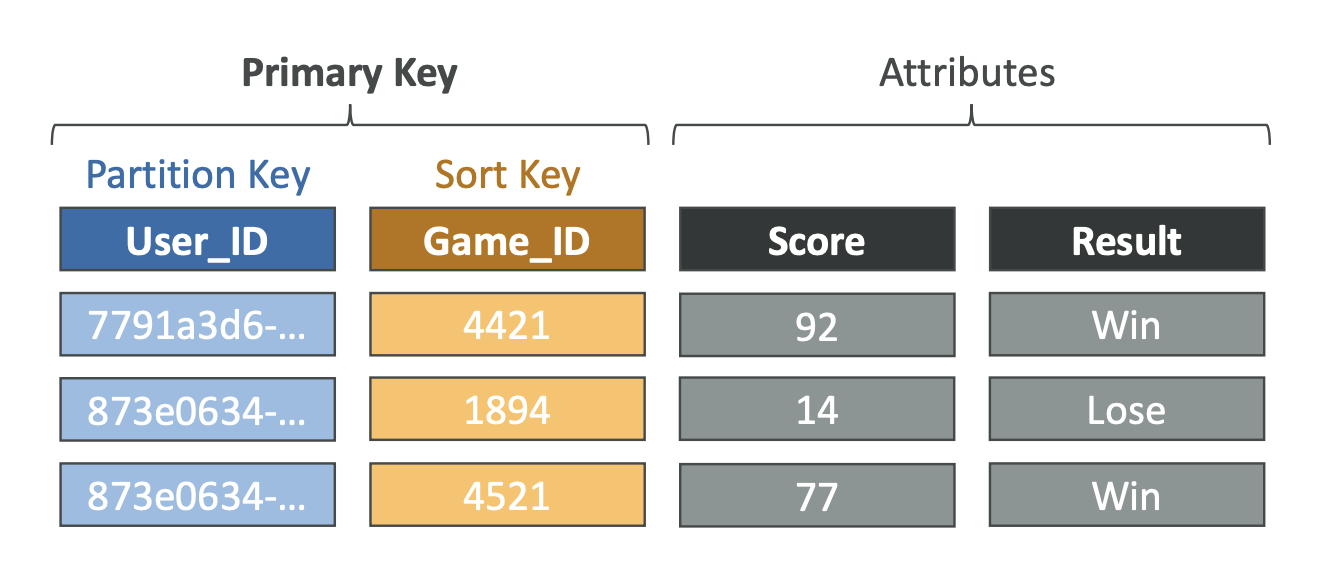
DynamoDB
- ms단위의 성능을 제공하는 Serverless NoSQL DB
- provisioned capacity mode : 지정된 용량 범위 내에서 auto scaling, 점진적인 증감이 있을 떄 활용
- on-demand capacity mode : 용량을 프로비저닝할 필요가 없음, 예측하기 어려운 workload에 따라 자동으로 scaling, 가파른 증감이 있을 때 활용
- key-value 저장소 -> elastiCache 대체 가능
- 세션 데이터를 저장하기 좋음 -> TTL 기능으로 일정 시간 뒤에 세션을 만료시킴
- 고가용성 -> Multi-AZ, 읽기/쓰기 분리
- DynamoDB와 완벽히 호환되는 캐싱 기능인 DAX cluster 제공 (ms단위의 읽기 성능)
- 보안/인증/인가 등의 기능이 모두 IAM을 통해 이루어짐
- DynamoDB Streams를 활성화하여 이벤트 처리 기능도 추가할 수 있음 (DynamoDB Streams : DB에 일어나는 변경사항을 감지하여 스트리밍) -> Lambda, Kinesis Data Streams등과 결합하여 이벤트 처리)
- Global Tables 기능 제공 -> 다수 region에 걸친 active-active 복제 가능
- 최대 35일의 자동 백업 옵션 (point in time restore 기능 활성화 필요) -> 자동백업 옵션을 활용하여 S3로 데이터를 내보내면, RCU사용없이 PITR window로 가능, S3에서 새로운 테이블로 가져올 때에도 WCU 사용없이 가능
- 장기 보관을 위한 On-demand 백업 옵션
- 빠르게 스키마를 변경하거나, 유연하게 변경해야할 때 유용
S3
- key-value 형태로 저장 -> 큰 객체를 저장할 때 유용, 여러 개의 작은 객체를 저장할 때는 비효율
- Serverless
- 객체 최대 크기 5TB
- Versioning 기능
- 다양한 스토리지 지원, Storage tiers : S3 Standard, S3 Infrequent Access, S3 Intelligent, S3 Glacier + tier 전환을 위한 lifecycle policy
- Versioing, Encryption, 복제, 영구삭제를 위한 MFA, logs 등의 기능들을 제공
- IAM을 통한 접근 보안, 버킷에 대한 접근 권한인 S3 Bucket Policy, Access Point 생성, ACL, CORS, 객체 잠금 기능 등 보안기능 제공
- Encryption : SSE-S3 (자체키 기반), SSE-KMS (관리할 수 있는 KMS키 기반), SSE-C, client-side 인증, TLS 전송보안
- S3 객체에 대한 대량 처리가 필요할 때 -> S3 Batch (use case : 비암호화 객체 일괄 암호화 등)
- 성능 : Multi-part upload (파일 병렬식 upload), S3 Transfer Acceleration, S3 Select (필요한 데이터만 검색)
- Automation : S3 Event Notifications (SNS, SQS, Lambda 등과 결합 가능)
- Use cases : 정적 파일, key-value 형태의 대량 file 저장소, 웹사이트 호스팅 등
DocumentDB (mongoDB)
- DocumentDB는 MongoDB의 Aurora 버전
- NoSQL DB
- mongoDB 기반
- JSON 데이터를 저장, 쿼리, 인덱스
- 배포개념이 Aurora와 유사 -> 완전 관리형 DB, 3 AZ에 걸친 고가용성
- 스토리지는 자동적으로 10GB까지 확장됨
- 초당 수백만개의 요청을 작업하기 위해 scale될 수 있음
Amazon Neptune

- Graph 데이터셋의 예시 : Social Network -> 과정(데이터)들이 모두 연결됨
- 사용자는 친구를 팔로우
- 댓글을 게시
- 다른 사용자의 댓글을 좋아요
- 게시글을 공유
- 완전 관리형 graph DB
- like Social Network
- 3 AZ에 걸쳐 최대 15개의 읽기전용 복제본을 가짐 -> 가용성이 높음
- 고도로 연결된 데이터 셋을 사용하는 app에 적합
- DB에 수십억 개의 관계를 저장
- 그래프를 쿼리할 때의 지연시간은 ms단위
- 위키피디아 지식 데이터와 같이 고도로 연결되어 있는 데이터에 적합 (추천 엔진, 소셜 네트워크 등)
Amazon Keyspaces (Apache Cassandra)
- Apache Cassandra를 지원
- Apache Cassandra : 오픈 소스의 NoSQL 분산 DB
- Serverless
- 완전 관리형, 확장성/가용성 높음
- app 트래픽에 따른 Auto Scaling 기능 제공
- 테이블 데이터는 여러 AZ에 걸쳐 세 번 복제됨
- 쿼리 수행에는 CQL(Cassandra Query Language)가 사용됨
- 지연시간 10ms
- 초당 수천 건의 요청 처리
- On-demand mode과 Provisioned mode with auto-scaling 두 가지 모드 지원 (DynamoDB와 동일)
- 암호화, 백업, 최대 35일의 PITR 기능 제공
- Use cases : IoT 장치 정보와 시계열 데이터 저장 등
Amazon QLDB
- Quantum Ledger Database
- Ledger : 금융 트랜잭션을 기록하는 장부
- 완전 관리형, Serverless, 고가용성 (3개 AZ에 걸쳐 복제)
- app 데이터의 시간에 따른 변경 내역을 검토하는 데 사용 -> 장부
- DB에 데이터를 기록하면 삭제하거나 수정할 수 없음 -> 불변 시스템
- QLDB Journal내에서 수정할 때마다 암호화 해시가 계산되어 추가됨 -> DB에서 삭제 불가, 수정본 추가방식(?)
- 일반 ledger blockchain framework보다 2~3배 나은 성능
- 관리형 블록체인과의 차이점은 QLDB는 탈중앙화 개념이 없음 -> Amazon 소유의 중앙 DB에서만 데이터 작성 가능

Amazon Timestream
- 시계열 DB
- 완전 관리형, 빠름, scale 가능, serverless
- 시계열(timestream) : 시간정보를 포함하는 point의 모음
- DB의 용량을 자동으로 확장/축소 가능
- 매일 수조 건의 이벤트를 저장/분석 가능
- 시계열 데이터에는 관계형 DB보다 시계열 DB를 활용하는 것이 속도나 비용측면에서 훨씬 이점
- SQL에 호환
- 최신 데이터는 메모리에 저장
- 과거 데이터는 비용 효율적인 스토리지 계층에 저장
- 시계열 분석 기능이 있어서 실시간으로 분석하고 패턴을 찾을 수 있음
- 전송중 암호화, 저장 암호화를 지원
- Use cases : IoT apps, 실시간 분석, 운영 app 등
- Architecture

반응형
'개발 > AWS' 카테고리의 다른 글
| [AWS] IAM 고급 (0) | 2024.06.25 |
|---|---|
| [AWS] CloudWatch and CloudTail (1) | 2024.06.11 |
| [AWS] Serverless (Lambda/DynamoDB/API Gateway) (1) | 2024.06.08 |
| [AWS] AWS Container Service (0) | 2024.06.01 |
| [AWS] SQS, SNS, Kinesis, Active MQ (0) | 2024.06.01 |