👉이전글에 이어서 이번 글에서는 MSA의 표준이라고 언급되는 아키텍처에 대해 다뤄보고, 해당 아키텍처를 반영하여 구현실습읕 진행해보겠습니다.
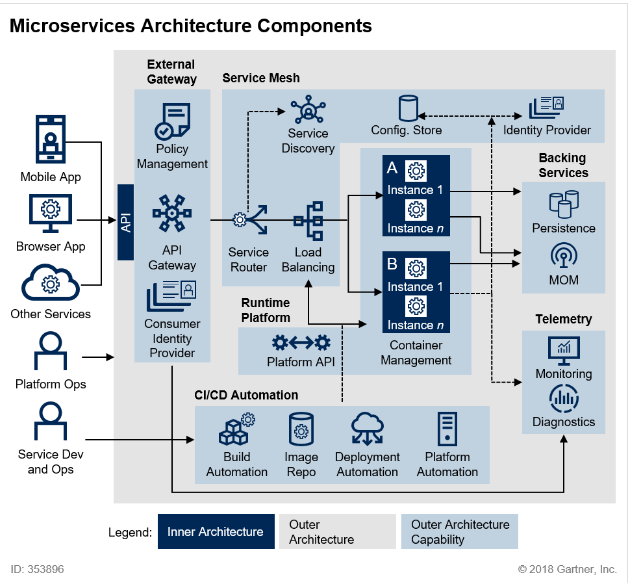
표준 MSA 아키텍처
위 사진에서 파란색 영역으로 구분된 부분을 Inner Architecture, 나머지 부분을 Outer Architecture라 부릅니다.
Inner Architecture : 실제 구현하려는 서비스와 직접적으로 연관되어 있는 부분입니다. 해당 부분들은 Container 환경에 배포됩니다. (ex. 주문관리 API 서버, 고객관리 API 서버 등)
Outer Architecture : 시스템이 원활히 돌아갈 수 있도록 시스템 전반적인 부분을 가리킵니다. 외부에서의 접근과 서버간의 연동을 일원화 시켜주는 External Gateway부터 MSA 환경의 데이터 동기화를 위해 사용되는 kafka와 DB서버와 같은 Backing Service 등이 이에 해당합니다.
본 글에서는 Outer Architecture를 구성하는 모듈을 하나씩 간략하게 알아보겠습니다.
A. External Gateway
External Gateway는 MSA환경의 내/외부에서 Micro 단위의 각 서버에 접근하는 것을 관리하는 모듈입니다. Micro 서버의 가장 앞단에 위치하여 모든 API로의 호출을 받고, 인증처리를 진행한 후에 각 서비스에 알맞게 트래픽을 전달합니다.
B. Service Mesh
Service Mesh는 MSA환경에서 방대한 양의 인스턴스로 인해 야기되는 복잡성과 불안정성을 보완하기 위해 도입된 아키텍처입니다. Service Mesh의 구현체인 경량화 Proxy를 통해 Load Balancing, Circuit Breaking 등과 같은 공통 기능들을 제공하여 복잡성과 불안정성을 해소합니다.
MSA 환경에서 야기되는 복잡성/불안정성
방대한 양의 인스턴스로 인해 모니터링 및 로깅에 어려움이 발생합니다.
내부 인스턴스간 통신이 기하급수적으로 증가함에 따라 내부 통신환경이 불안정할수록 MSA 시스템에 큰 타격을 줄 수 있습니다.
Service Mesh에서 제공하는 대표적 기능들
Service Discovery : MSA 환경에서 동적으로 IP/PORT가 변하는 인스턴스를 효과적으로 호출하기 위해 사용되는 패턴입니다. Eureka와 같은 Service Registry가 사용가능한 인스턴스의 목록을 관리하고, 호출할 인스턴스의 IP/PORT를 반환해줍니다. 대표적인 방식으로 Client-Side Discovery, Server-Side Discovery, registration 방식이 있습니다.
Load Balancing : Service Mesh로 들어온 트래픽을 적절하게 분배하여 인스턴스에 전달합니다. MSA 환경에서 하나의 서버는 여러 개의 인스턴스를 생성하여 Scale-Out할 수 있는데, Eureka와 같은 Service Registry가 적절한 규칙을 통해 부하를 분산시켜줍니다.
Circuit Breaking : Circuit Breaking기능은 이러한 점을 보완하기 위한 기술입니다. 각 인스턴스는 Close, Open, Half-open 세 가지 상태로 Circuit Breaking 공통 기능을 사용하게 되고, 호출하는 서비스에 문제가 발생할 경우 상태를 Open상태로 전환하여 해당 서비스로의 호출에 대한 응답을 대기하지 않게 됩니다. Circuit Breaking은 회로차단기에서 차용한 개념입니다. 기존에는 하나의 서비스에 장애가 발생하면 해당 서비스를 호출하는 서비스가 대기상태가 되고, 대기상태를 또 호출하는 서비스도 대기상태로 되어 많은 컴퓨팅 리소스를 잡아먹게 됩니다. 이로 인해 장애가 확산되어 전체 시스템에 악영향을 초래할 수가 있는데, Circuit Breaking기능을 활용하면 이를 방지할 수 있습니다.
Retry and Timeout : 타 인스턴스로의 요청이 실패할 경우, 재요청 보내는 Retry 시간을 설정할 수 있고, Timeout 시간을 설정하여 일정시간이 지난 요청을 종료할 수 있습니다.
TLS : 보안을 위해 인스턴스간의 트래픽을 암호화할 수 있는 기능입니다.
Distributed Tracing : 분산 시스템의 성능을 디버깅하기 위해 트래픽을 추적할 수 있습니다. 이를 통해, 병목 현상을 식별하고 요청 및 응답 시 내부에서 소요되는 시간을 확인할 수 있습니다.
이 밖에도 Monitoring, Logging 등의 많은 기능을 수행할 수 있습니다.
Service Mesh 구현
각 Micro Service 앞단에 사이드카 형태로 경량화 Proxy를 배치하여 Retry and Timeout, Circuit Breaking 등과 같은 공통기능을 수행하게 함으로써 비즈니스 로직과 공통기능을 분리시키고, 공통기능을 통해 방대한 양의 인스턴스 환경을 안정적으로 운영할 수 있습니다.
대표적인 Service Mesh 툴로 Istio와 linkerd 등이 있습니다. 해당 툴은 Eureka와는 달리 Java에 종속적이지 않다는 장점이 있어 널리 활용되고 있습니다.
C. Backing Services
Backing Services모듈은 시스템의 데이터 관리를 담당하는 모듈입니다.
Persistence : RDBMS와 NoSQL 데이터를 영구히 저장할 수 있는 공간을 제공합니다. (ex. oracle, postgres 등) 이를 통해 DB 인스턴스가 예기치 못하게 종료되어도 데이터는 유지할 수 있습니다.
Cache: 데이터 캐쉬를 저장할 수 있는 공간을 제공합니다. (ex. redis) 마찬가지로 캐싱처리를 담당하는 인스턴스가 종료되어도 데이터를 유지할 수 있습니다.
Message Broker: Message Queue 등과 같은 기술을 활용하여 인스턴스간 데이터 정합성 유지를 도모할 수 있습니다. (ex. kafka)
D. Runtime Platform
관리해야하는 인스턴스의 양이 증가함에 따라 관리의 복잡성을 해결하기 위해 Container Orchestration이 해당 모듈에서 사용될 수 있습니다. 대표적인 툴로 Kubernetes가 있습니다.
방대한 인스턴스로 서비스를 운영하기 위해 Container기술을 도입하게 되었습니다. 해당 기술은 서비스간 독립적인 배포와 운영이 가능하고, 인스턴스의 빠른 생성과 제거가 가능하여 빠른 오토스케일링 기능과 배포를 도모할 수 있게 되었습니다. 그리고 Container환경으로 구성되어 있는 방대한 양의 인스턴스를 관리하기 위해 Container기술에 초점이 맞춰져 있는 Container Orchestration툴이 사용되기 시작했습니다.
위에서 언급된 Service Mesh와 Container Orchestration은 방대한 양의 인스턴스로 인해 야기되는 복잡성을 해소한다는 공통점이 있지만, Service Mesh는 MSA 환경의 안정성을 위해 공통기능을 제공한다는 데에 초점이 맞춰져있는 반면, Container Orchestration은 Container기술에 초점을 맞추어 서비스 운영을 위한 경량화된 환경을 제공하여 운영효율성을 높이는 데에 초점이 맞춰져 있습니다.
E. Telemetry
Telemetry는 MSA환경에 배포되어있는 인스턴스들의 로그와 지표들을 한데 모아 관리하는 모듈입니다. 이를 통해 서비스 호출 트래픽을 추적할 수 있고, 로깅기능과 모니터링 기능을 제공할 수 있습니다.
대표적인 툴로 Elastic Search와 Prometheus, Grafana 등이 있습니다.
F. CI/CD Automation
CI : Continuous Integration, 지속적 통합, 새로운 코드의 변경사항이 지속적으로 빌드 및 테스트 되어 공유 레포지토리에 통합되는 것을 의미합니다. 이를 위해 필요한 대표적 형상관리 툴로 Git이 있습니다.
CD : Continuous Deployment, 지속적 배포, 새로운 코드의 변경사항이 CI 과정을 거쳐 공유 레포지토리에 통합되면 이를 Production환경까지 자동배포하는 것을 의미합니다. 이를 위해 필요한 대표적인 툴로 Jenkins가 있습니다.
지난 23년 12월 말에 파트 내에서 개발한 UI화면의 조회과정에서 부하가 발생하였습니다. 이에 따라 인프라팀으로부터 쿼리 튜닝 요청이 왔습니다.
먼저 저는 문제의 쿼리를 실행시키는 화면을 먼저 알아봤습니다. 해당 화면은 조회를 위해 여러 키 값을 입력할 수 있는 구조로 되어 있는데, 이 중, 필수 파라미터는 최대 7일까지 입력할 수 있는 기간 데이터와 최대 1개까지 입력할 수 있는 통신국사였습니다.
해당 화면의 조회쿼리 성능이 나쁘다는 전제가 있어서 필수 파라미터만 키 값으로 넣되, 조회 기간은 1일로 설정하여 조회를 시도해봤습니다.
그 결과, 화면은 바로 멈춰버리고... 모니터링 툴인 파로스상으로 확인해봤을 때, 해당 트랜잭션의 실행은 15~20분정도 지나서야 종료가 되었습니다. 기간을 1일로 잡아도 이정도의 성능을 보이는 것을 보니까... 생각보다 심각하구나라는 걸 인지하게 되었어요.
2. 튜닝 과정
먼저 저는 문제의 쿼리를 파악해봤습니다. 아래 쿼리는 파로스상 가장 오랜시간의 지연을 가진 쿼리입니다.
SELECT count(*) totalCount
FROM (
SELECT crt.*
FROM PNA_CIRCUITATHN_RQT_TXN crt,
TB_OFFICE office,
PNA_ORTR_TELNO_TXN tel,
WHERE
crt.OBDNG_ID=office.OFFICESCODE(+)
AND crt.ORDR_TRT_NO=tel.ORDR_TRT_NO(+)
AND tel.CHG_BEFAFT_TYPE_CD(+) = '2'
AND tel.TEL_NO_TYPE_CD(+) = '1'
AND crt.OBDNG_ID IN ('R02471')
AND crt.RQT_DT BETWEEN TO_DATE('20240104' || '000000', 'YYYYMMDDHH24MISS')
AND TO_DATE('20240104' || '235959', 'YYYYMMDDHH24MISS')
);
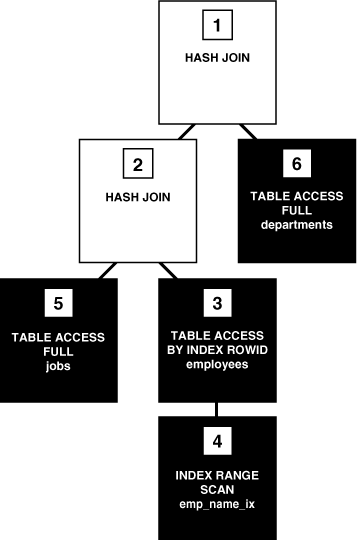
위 쿼리에서 조건 키값으로 입력한 통신국사의 코드는 OBDNG_ID이고, 기간 데이터는 RQT_DT컬럼의 데이터로 입력됩니다. 지연의 원인을 파악하기 위해 실행계획을 확인해봤습니다.
Plan hash value: 3635163560
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 39 | | |
| 2 | NESTED LOOPS OUTER | | 1 | 39 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| PNA_CIRCUITATHN_RQT_TXN | 1 | 25 | 1 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | PNA_CIRCUITATHN_RQT_TXN_IX_02 | 1 | | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PNA_ORTR_TELNO_TXN_PK | 1 | 14 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$ABC8FBB0
3 - SEL$ABC8FBB0 / CRT@SEL$2
4 - SEL$ABC8FBB0 / CRT@SEL$2
5 - SEL$ABC8FBB0 / TEL@SEL$2
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("CRT"."RQT_DT">=TO_DATE(' 2024-01-04 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"CRT"."OBDNG_ID"='R02471' AND "CRT"."RQT_DT"<=TO_DATE(' 2024-01-04 23:59:59', 'syyyy-mm-dd
hh24:mi:ss'))
filter("CRT"."OBDNG_ID"='R02471')
5 - access("CRT"."ORDR_TRT_NO"="TEL"."ORDR_TRT_NO"(+) AND "TEL"."TEL_NO_TYPE_CD"(+)='1' AND
"TEL"."CHG_BEFAFT_TYPE_CD"(+)='2')
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - (#keys=0) COUNT(*)[22]
2 - (#keys=0)
3 - "CRT"."ORDR_TRT_NO"[VARCHAR2,11]
4 - "CRT".ROWID[ROWID,10]
그런데... 실행계획상 성능이 나쁘진 않았습니다. 해당 실행계획을 가진 쿼리가 15분 이상을 지연시킨 쿼리라고 하니... 이해가 되질 않았어요. 모니터링 툴이었던 파로스가 쿼리 실행시간을 제대로 못 잡은건지도 의심이 들었습니다.
그래서 실제 실행시켰던 쿼리의 실행계획이 궁금했고, 인프라팀에 문의했습니다. 실행계획 성능과 실제 지연시간과 차이가 발생한 이유로 해당 쿼리에 바인드 변수가 사용되었기 때문일 수도 있다는 답변을 받았습니다.
바인드 변수 쿼리
바인드 변수 쿼리는 변수가 사용된 쿼리입니다. 아래와 같은 형태로 사용됩니다. SELECT * FROM tb_test WHERE id = :id; 위 쿼리에서 조건절의 :id로 표현된 부분에 여러 id값이 입력되는 바인드 변수입니다.
위 쿼리에서처럼 바인드 변수 쿼리로 실행되지 않고, 아래처럼 상수 형태로 입력되어 실행된다면 쿼리는 한번 사용된 실행계획을 재사용하는 것이 아닌 새로 실행계획을 수립하는 Hard parsing이 진행되어 성능상 비효율이 발생합니다.
SELECT * FROM tb_test WHERE id = 1;
SELECT * FROM tb_test WHERE id = 2;
SELECT * FROM tb_test WHERE id = 3;
SELECT * FROM tb_test WHERE id = 4;
SELECT * FROM tb_test WHERE id = 5;
그렇기 때문에 성능상 이점을 위해서는 바인드변수 쿼리를 사용해야 합니다. 바인드변수 쿼리를 사용하게 되면, 바인드 변수의 값만 바꿔서 쿼리를 실행시킬 때, 해당 쿼리에 맞는 이미 실행되었던 실행계획을 재사용하여 실행시키는 Soft parsing이 진행되기 때문에 더욱 빠르게 실행시킬 수 있습니다.
하지만 맹점이 있었습니다. 바인드 변수에 해당하는 조건의 값을 예측하기가 어려워 잘못된 실행계획을 수립할 수도 있습니다. 본 글에서 언급한 쿼리의 비효율도 해당 맹점으로 인해 발생했습니다. 그리고 아래는 바인드 변수 쿼리로 수립된 실행계획입니다.
위 쿼리의 비효율은 잘못된 인덱스를 스캔하는 실행계획을 수립했기 때문에 발생하였습니다. 실행계획상으로 볼 수 있다시피 상수쿼리는 PNA_CIRCUITATHN_RQT_TXN_IX_02 인덱스를 스캔한 반면에, 바인드변수 쿼리는 PNA_CIRCUITATHN_RQT_TXN_IX_03 인덱스를 스캔했어요. 3번 인덱스를 스캔한 시점에서 쿼리 실행에 많은 비용이 발생하게 됩니다.
튜닝 대상의 쿼리에는 여러개의 인덱스가 생성되어 있는데, 그 중 대표적으로 봐야할 두 개의 인덱스가 있습니다.
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_02 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(RQT_DT, OBDNG_ID, RQT_TRT_RESLT_SBST)
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_03 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(OBDNG_ID, ORDR_TYPE_ID, ORDR_TRT_TYPE_SEQ)
쿼리에서 확인할 수 있는 것처럼 조건절에는 OBDNG_ID컬럼과 RQT_DT컬럼이 있고, 해당 컬럼이 모두 있는 2번 인덱스를 스캔해야 효율적인 쿼리 실행이 가능합니다. 하지만 바인드변수 쿼리는 OBDNG_ID컬럼만 있는 3번 인덱스를 스캔했는데요.
이러한 잘못된 스캔의 원인으로 바인드변수 쿼리 실행시에는 변수에 어떤 값이 입력될지 몰라서 Optimizer가 조회할 데이터의 양을 예측하지 못하는데 있다고 추측됩니다. OBDNG_ID컬럼의 경우, in절이라서 변수의 갯수로 어느정도 예측을 할 수 있지만, RQT_DT컬럼의 경우는 예측이 안되어 OBDNG_ID가 선행컬럼으로 있는 3번 인덱스를 스캔하게 된 것이죠.
해결방안
힌트 추가
첫번째 개선방안은 인덱스 힌트를 추가하여 특정 인덱스를 강제로 스캔하는 방안이었습니다. 아래는 인덱스 힌트가 추가된 쿼리입니다.
SELECT count(*) totalCount
FROM (
SELECT /*+ index (crt PNA_CIRCUITATHN_RQT_TXN_IX_02) */
crt.*
FROM PNA_CIRCUITATHN_RQT_TXN crt,
TB_OFFICE office,
PNA_ORTR_TELNO_TXN tel,
WHERE
crt.OBDNG_ID=office.OFFICESCODE(+)
AND crt.ORDR_TRT_NO=tel.ORDR_TRT_NO(+)
AND tel.CHG_BEFAFT_TYPE_CD(+) = '2'
AND tel.TEL_NO_TYPE_CD(+) = '1'
AND crt.OBDNG_ID IN ('R02471')
AND crt.RQT_DT BETWEEN TO_DATE('20240104' || '000000', 'YYYYMMDDHH24MISS')
AND TO_DATE('20240104' || '235959', 'YYYYMMDDHH24MISS')
);
힌트는 아래와 같은 형태로 추가되어 쿼리 실행시에 특정 인덱스를 고정적으로 스캔할 수 있도록 강제할 수 있습니다. /*+ index (crt PNA_CIRCUITATHN_RQT_TXN_IX_02) */ 위 인덱스 힌트는 사전에 검증된 성능의 2번 인덱스를 스캔하기 위한 구문입니다.
하지만 힌트가 추가되었을 때의 문제는 바인드 변수에 값이 랜덤하게 입력되는데, 선행컬럼이 OBDNG_ID로 구성되어 있는 인덱스를 스캔하는 것이 더 성능이 좋은 케이스도 분명 존재한다는 것입니다. 3번 인덱스처럼 말이죠. 하지만 3번 인덱스에는 RQT_DT컬럼이 없죠.
인덱스 추가
위에서 언급한 것처럼 바인드 변수에 입력되는 값에 따라 OBDNG_ID 선행컬럼의 인덱스를 스캔하는 것이 더 효율적일 수도 있습니다. 이러한 경우를 대비해서 아래 6번 인덱스를 추가하기로 결정했습니다.
CREATE INDEX CUI_OWN.PNA_CIRCUITATHN_RQT_TXN_IX_06 ON CUI_OWN.PNA_CIRCUITATHN_RQT_TXN(OBDNG_ID, RQT_DT, RQT_TRT_RESLT_SBST)
기존 검증된 성능의 2번 인덱스와 동일한 컬럼 구성의 6번 인덱스를 생성하되, 선행컬럼을 RQT_DT에서 OBDNG_ID로 바꾸어 OBDNG_ID 선행컬럼의 인덱스를 스캔하는 것으로 Optimizer가 실행계획을 수립해도 RQT_DT 컬럼도 인덱스로 같이 스캔할 수 있게끔 할 수 있습니다.
3번 인덱스가 아닌 6번 인덱스를 스캔하는 것을 실행계획상 확인하였고, UI에서 조회시에도 기존에는 기간을 하루로 설정하여 조회해도 15분 이상이 소요되었는데, 인덱스가 추가 반영된 이후에는 기간을 최대 7일까지 설정해도 조회시간이 최대 3초 이내로 마무리된 것까지 확인하여 성능이 크게 개선된 것을 확인하였습니다.
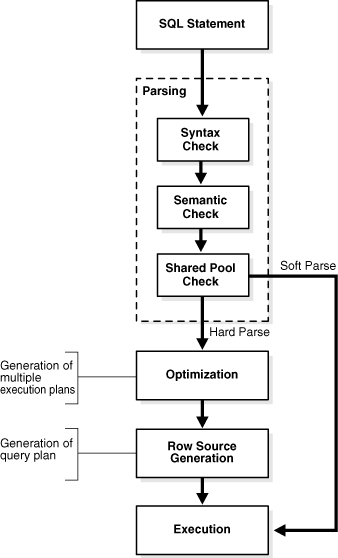
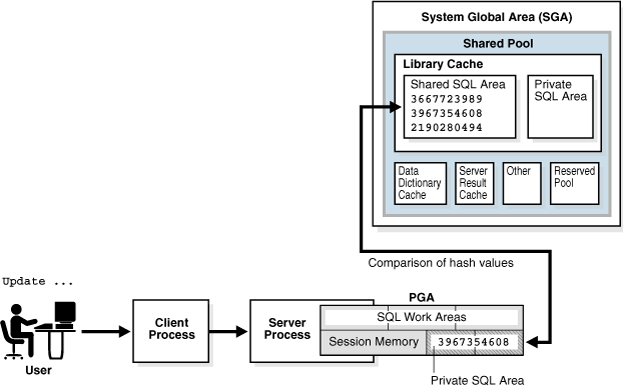
Application에 의해 SQL이 실행되면 DB서버에서는 PGA(Program Global Area) 내부에 private SQL area를 생성하고, 이를 가리키는 포인터인 Cursor를 생성하여 실행된 SQL을 파싱할 준비를 합니다.
PGA (Program Global Area) : 각각의 Application이 독자적으로 사용하는 Oracle 메모리 영역
private SQL area : 실행된 SQL과 처리를 위한 정보가 담기는 PGA 내부의 메모리 영역, 처리를 위한 정보로 바인드 변수 값과 쿼리 실행 상태 등의 정보가 있음.
Syntax Check
실행된 SQL이 문법상 유효한지 확인하는 과정입니다. 예를들어, 아래 쿼리는 해당 과정에서 오류로 반환될 것입니다. (FORM을 FROM으로 수정 필요)
SELECT * FORM employees;
Semantic Check
실행된 SQL이 문법상 유효하다면, 이제 의미상으로 유효한지 본 과정에서 확인하게 됩니다. 예를들어, 아래 쿼리가 실행된다고 가정해봅시다.
SELECT * FROM nonexistent_table;
위에서 실행된 쿼리의 테이블 nonexistent_table이 실제로 존재하지 않는 테이블이라고 가정했을 때, 위 실행쿼리는 의미상 유효하지 않으므로 본 과정에서 에러를 반환하게 됩니다.
Shared Pool Check
쿼리 성능에 크게 영향을 미치는 과정입니다. unique한 각각의 SQL에는 해시값의 SQL_ID가 있습니다. 동일한 SQL은 동일한 SQL_ID를 갖죠.
본 과정에서는 실행된 쿼리의 SQL_ID가 Shared SQL Area에 존재하는지 확인하게 되고, 동일한 SQL_ID가 존재하지 않는다면 Hard Parsing을 진행하게 됩니다.
Shared SQL Area : 각 PGA (Program Global Area)에서 실행된 SQL과 실행계획 등과 같은 정보를 공유하는 메모리 공간
동일한 SQL_ID가 존재한다면, 추가적인 semantic check와 environment check를 거칩니다. 실행된 SQL이 동일한 SQL_ID를 가진 SQL과 문법상 같은 SQL을 가졌다고 하더라도 의미상/환경상 차이를 보일 수 있기 때문이죠. 그리고 위의 추가적인 검증절차를 통과하지 못해도 Hard Parsing을 진행하게 됩니다.
모든 검증절차를 통과한 SQL만이 Soft Parsing을 진행할 수 있게 됩니다.
Soft Parsing : 기존 실행되었던 실행계획을 재사용하여 쿼리를 실행
Hard Parsing : Optimization 단계를 거쳐 새로운 실행계획을 수립하여 쿼리를 실행
SQL Optimization
본 과정에서 새로운 실행계획이 수립됩니다. SQL engine이 바이너리 형태의 초기 실행계획을 row source generator에게 전달하면, row source generator는 전달받은 바이너리 형태의 초기 실행계획을 row source tree형태로 생성하여 우리가 흔히 알고 있는 실행계획을 생성해줍니다.
그리고 SQL engine이 다시 생성된 실행계획을 실행시키는 것으로 SQL의 처리가 완료됩니다.
위에서 참고한 Oracle 가이드에는 실제로 최적화가 어떻게 이루어져 최적의 실행계획을 추출하는지에 대한 내용이 없어서... 관련 내용은 추가적인 서핑이 필요합니다. 다음 글에서는 SQL engine이 어떤 정보를 기반으로 어떻게 최적화를 진행하는지, 어떻게 쿼리를 작성하고 튜닝하는 것이 바람직한지 알아보겠습니다.
팀내 관리자용 웹 사이트의 SpringBoot 서버를 개발하면서 겪은 JPA 활용 시행착오를 공유하고자 합니다. 버전정보는 아래와 같습니다. Java 1.8, SpringBoot 2.4
문제 상황
관리자용 웹 사이트에서 활용하는 정보를 DB로부터 조회하고 저장하는 CRUD API 개발을 사전에 진행한 상황이었습니다. 그 중, DB에 데이터를 update하는 코드는 아래와 같았습니다.
@Service
@RequiredArgsConstructor
public class InfoService {
private final InfoRepository infoRepository;
@Transactional
public CommonResponse<String> updateInfo(InfoReq infoReq) {
CommonResponse<String> response = new CommonResponse<>();
try {
Info info = Info.builder()
.id(infoReq.getId())
.name(infoReq.getName())
.date(infoReq.getDate())
.note(infoReq.getNote())
.build();
infoRepository.save(info);
} catch (Exception e) {
response.setSuccess(false);
response.setData(e.toString());
e.printStackTrace();
}
return response;
}
}
DB에 update할 정보를 Rest API Controller 파라미터로부터 받고, 해당 파라미터 정보를 update할 엔티티 오브젝트에 빌더를 활용하여 세팅하고, JPA의 save메서드를 활용하여 DB에 반영하는, 겉으로 보기에는 문제가 없어보이는 일반적인 코드로 보였습니다.
이후, 👉이전글에서 확인된 것처럼 Scheduler를 개발하게 되었고, 위 코드의 Info 엔티티에 필드가 추가됩니다.
이때, 사실 이미 작성된 기존코드를 크게 신경쓰지 않았습니다. 기존 update코드에서 update가 진행될 필요가 없는 데이터에 대한 필드가 추가되었고, update 진행 시에 추가된 필드는 null로 세팅되어 JPA 자체적으로 값이 세팅되어 있는 필드만 실제 DB에 반영할 것이라고 생각했기 때문입니다. (완벽한 착각)
하지만 생각과는 달랐어요. 신규로 추가된 필드에 DB client 툴에서 쿼리를 실행하여 직접 데이터를 사전에 넣은 상태에서 기존 update코드를 실행시키는 update요청을 보내어 DB에 값을 update시키면, 사전에 직접 넣은 데이터는 null로 다시 update가 되는 현상을 확인하였습니다.
문제의 원인
앞서 언급했던 것처럼 JPA 자체적으로 값이 세팅되어 있는 필드만 실제 DB에 반영할 것이라고 생각했습니다. 하지만 이는 잘못된 생각이었어요.
공신력이 있는... 향로님의 👉참고글에서 확인해본 결과, JPA는 기본값으로 update를 실행할 때, 전체 필드를 대상으로 진행되는 것으로 설정되어 있다고 합니다.
그래서 신규 필드에 대한 데이터 세팅 작업이 없는 기존 update 코드가 실행이 된다면, 신규 필드에는 자동으로 null로 세팅이 될 것이고, JPA는 기본값으로 설정되어 있기 때문에 null 데이터를 포함한 전체 필드를 대상으로 Update를 진행하게 되는 것입니다.
그래서 Update가 필요한 컬럼에 대해서만 DB Update가 진행될 수 있도록 코드를 수정해야 했습니다.
변경된 부분만 Update하는 방법
변경된 부분만 실제 DB에 Update하는 방법으로 아래 세 가지 방법을 고려하였습니다.
1. 조회 후, 전체 데이터 세팅
신규로 추가된 필드가 null로 세팅되어 Update되는 것이라면... 신규 필드에 대한 데이터를 DB에서 조회해온 후에 값을 세팅해서 save하면 되는 문제아닌가? 간단히 생각할 수 있는 솔루션입니다.
하지만 update할 엔티티를 builder를 활용하여 새로 생성하여 save하고 있었습니다. 그렇기 때문에 엔티티에서 각 필드에 대한 값을 하나하나 정성스럽게 세팅해줘야 합니다. 이는 해당 엔티티에 새로 신규 필드가 추가된다면, builder를 활용한 모든 코드에 필드를 추가해줘야한다는 것을 의미했습니다.
향후 유지보수에 있어서 상당한 비효율이 예상되었기 때문에 pass!
@Service
@RequiredArgsConstructor
public class InfoService {
private final InfoRepository infoRepository;
@Transactional
public CommonResponse<String> updateInfo(InfoReq infoReq) {
CommonResponse<String> response = new CommonResponse<>();
try {
Info curInfo = infoRepository.findById(infoReq.getId()); // 엔티티에 세팅할 값을 조회
Info info = Info.builder()
.id(infoReq.getId())
.name(infoReq.getName())
.date(infoReq.getDate())
.note(infoReq.getNote())
.newField(curInfo.getNewField()) // 신규 필드에 값 세팅 추가
.build();
infoRepository.save(info);
} catch (Exception e) {
response.setSuccess(false);
response.setData(e.toString());
e.printStackTrace();
}
return response;
}
}
2. @DynamicUpdate 어노테이션 선언
@DynamicUpdate 어노테이션을 선언하면, 해당 어노테이션이 선언된 entity에서 수정된 필드를 대상으로만 DB에 update를 실행하게 됩니다. 👉해당글 참고
@Table(name="tb_info")
@Entity
@Getter
@Builder
@ToString
@NoArgsConstructor
@AllArgsConstructor
@DynamicUpdate // 어노테이션 추가
public class Info {
@Id
@Column(name = "id")
private int id;
@Column(name = "name", length = 10)
private String name;
@Column(name = "date")
private LocalDateTime date;
@Column(name = "note", length = 50)
private String note;
}
앞서 언급했던 것처럼 JPA는 기본 설정으로 모든 필드 대상으로 Update 되게끔 설정되어 있다고 합니다. 그런데 @DynamicUpdate 어노테이션을 활용하면 변경된 필드 대상으로만 Update하는 쿼리를 실행하게 되죠.
하지만 JPA의 기본값으로 모든 필드가 Update 되게끔 설정된 이유를 알고나면, @DynamicUpdate 어노테이션의 활용을 한번 더 고민하게 될 것입니다.
JPA 설정으로 변경된 필드에 상관없이 모든 필드가 Update가 될 때의 장점은 아래와 같습니다.
생성 쿼리가 항상 동일하여 SpringBoot 서버 실행 시점에 쿼리를 미리 만들어 사용할 수 있습니다.
DB 입장에서 쿼리 재사용이 가능합니다. (DB는 사전에 실행한 쿼리를 캐싱해놓고, 동일 쿼리가 실행되었을 때 캐싱된 쿼리를 실행함)
모든 필드를 Update할 때의 장점이 위와 같기 때문에 @DynamicUpdate 어노테이션을 사용했을 때, 위 장점들을 활용하지 못하고 쿼리를 매번 새로 생성하여 실행하게 됩니다. 즉, 성능상 비효율을 초래할 수 있습니다. 그래서 이 방식도 pass!
3. Dirty Checking 활용
Dirty Checking이란?
먼저 Dirty Checking에 대해 간단히 짚고 넘어가겠습니다.
Dirty Checking은 JPA에서 트랜잭션이 끝나는 시점에 변경이 있는 엔티티를 DB에 자동으로 반영하는 것을 의미합니다. 즉, 영속성 컨텍스트가 관리하는 엔티티에 setter등을 활용하여 필드에 값을 세팅하는 등 변경이 생긴다면, 트랜잭션이 끝나는 시점에 엔티티의 마지막 상태로 DB update를 진행하게 된다는 것입니다.
여기서 주목해야할 부분은 영속성 컨텍스트가 관리하는 엔티티의 의미입니다. 예제로 간단하게 표현해보면
JpaRepository로 조회해온 Entity : 영속
detach된 Entity : 준영속
Builder, 생성자 등을 통해 새로 생성한 Entity : 비영속
여기서 영속상태인 Entity를 영속성 컨텍스트가 관리하는 엔티티로 볼 수 있고, 해당 Entity에서 변경이 생길 경우, 별도 save 메서드를 통해 Update를 수행하지 않아도 트랜잭션이 끝나는 시점에 DB에 변경사항이 반영됩니다.
Dirty Checking 수행을 원하지 않을 수도 있습니다. 해당 기능을 막기 위해서 @Transactional(readOnly = true) 어노테이션의 readOnly 옵션을 true로 설정해주면 됩니다.
Dirty Checking 활용
Dirty Checking 기능을 활용하려면 영속성 컨텍스트가 관리하는 엔티티를 활용해야합니다. 하지만 어차피 update를 하기 전에 모든 값을 세팅해주어야 하기 때문에 사전에 조회하는 작업이 필요하긴 하죠. 그렇기 때문에 값을 사전 조회한 Entity(영속성 컨텍스트가 관리하는 Entity)에 필드 값을 변경해주어 모든 값에 대해 Update가 될 수 있도록 코드를 수정할 것입니다.
해당 방식을 활용하면 종합적으로 아래와 같은 장점을 얻을 수 있습니다.
모든 필드를 Update하는 동일 쿼리를 사용하기 때문에 성능상 이점이 있음
모든 필드를 누락없이 Update시킬 수 있음
@Service
@RequiredArgsConstructor
public class InfoService {
private final InfoRepository infoRepository;
@Transactional
public CommonResponse<String> updateInfo(InfoReq infoReq) {
CommonResponse<String> response = new CommonResponse<>();
try {
Info info = infoRepository.findById(infoReq.getId()); // 영속성 컨텍스트가 관리하는 Entity
info.setId(infoReq.getId());
info.setName(infoReq.getName());
info.setDate(infoReq.getDate());
info.setNote(infoReq.getNote());
} catch (Exception e) {
response.setSuccess(false);
response.setData(e.toString());
e.printStackTrace();
}
return response;
}
}
위 코드는 어느정도 보완이 된 코드이지만, 여전히 위 1번 방식에서 언급한 유지보수의 효율이 떨어지는 코드이고, Entity에서 지양되어야 하는 Setter 메서드가 활용되고 있습니다. 👉Setter지양이유 글 참고
전체 값을 조회해온 Entity에 위 코드에서 새로 추가한 메서드를 활용하여 실제 Update가 진행되어야할 필드의 값만 세팅되도록 할 것입니다.
이를 통해 Setter 메서드를 활용할 필요가 없고, 가독성도 높일 수 있게 되었습니다.
이 뿐만 아니라 Entity를 새로 생성해서 Update해야하는 경우도 있을 수 있습니다. Entity를 새로 생성해야할 경우를 대비해서 autoUpdateDate, updateAll과 메서드를 활용하여 값이 세팅될 수 있도록 하였고, 신규 필드가 추가될 때마다 updateAll 메서드만 수정될 수 있도록 하여 유지보수의 효율성을 높였습니다.
그리고 아래는 위 Entity를 반영한 최종 Update 코드입니다.
@Service
@RequiredArgsConstructor
public class InfoService {
private final InfoRepository infoRepository;
@Transactional
public CommonResponse<String> updateInfo(InfoReq infoReq) {
CommonResponse<String> response = new CommonResponse<>();
try {
Info info = infoRepository.findById(infoReq.getId()); // 영속성 컨텍스트가 관리하는 Entity
info.updateField(infoReq.getName(), infoReq.getDate(), infoReq.getNote());
// 트랜잭션이 끝나면 info 엔티티 Update 수행
} catch (Exception e) {
response.setSuccess(false);
response.setData(e.toString());
e.printStackTrace();
}
return response;
}
}
작년 3월, 사내 프로젝트에서 Spring Scheduler 개발을 진행했었습니다. 👉이전글 참고
그리고 사내 관리자용 웹 서버를 nodejs -> spring boot 서버로 이관하는 작업을 진행하면서 다시한번 Spring Scheduler 개발을 진행할 기회가 생겼습니다.
본 글을 통해 Spring Scheduler 개발을 이전보다 어떻게 더 세련되게(?) 진행했는지에 대해서 다뤄보고자 합니다. 이번 개발에는 java8 에서 제공하는 기능들을 적극 활용하였는데, 관련된 부분은 👉람다표현식과 함수형인터페이스글에서 확인 바랍니다.
개발목표
개발 목표는 비슷합니다.
관리자가 스케줄러의 동작을 조절할 수 있어야 함 (시작/중지/주기변경)
스케줄러 동작의 조절은 런타임환경에서도 가능해야 함.
어떻게 관리자가 스케줄러의 동작을 런타임 환경에서 조절할 수 있는지에 대해서는 👉이전글을 참고바랍니다.
그리고 추가된 목표는 코드의 중복을 최소화하고, 확장이 보다 유용한 형태로 구현하는 것이었습니다. 이를 위해 함수형 인터페이스에 대한 이해가 필요했습니다. 👉람다표현식과 함수형인터페이스글 참고
이전 scheduler
이전 Scheduler 코드에는 중대한 문제점이 있었습니다.
특정 기능을 위한 스케줄러가 추가될 때, 각각의 클래스로 구현을 진행했습니다. 그런데 이러한 구현은 많은 낭비를 낳게 됩니다.
스케줄러 하나가 추가될 때마다 별도의 클래스를 생성해야 했고, 해당 클래스에는 다른 스케줄러 클래스와의 중복 코드도 같이 작성해야 했습니다. 또한, 클래스를 추가할 뿐만 아니라 기존 스케줄러 관련 코드에도 많은 수정이 필요했습니다. 자세한 코드는 👉이전글을 참고해주세요.
새롭게 구현하는 Scheduler는 이러한 비효율을 만들고 싶지 않았습니다.
좀더 세련된 Scheduler 구현하기 (feat. 함수형 인터페이스)
새롭게 Scheduler를 구현할 수 있게된 계기는 👉람다표현식과 함수형인터페이스글에서도 확인할 수 있는 것처럼 java8 이후부턴 함수의 동작도 파라미터에 입력할 수 있는 변수로 관리할 수 있다는 것을 알게된 것이었습니다.
이러한 java8의 특징을 적극 활용하여 Scheduler가 실행해야할 핵심적인 비즈니스 로직을 변수화시켜서, Scheduler의 공통로직(ex. Scheduler 시작/중지/주기변경, 초기화, API 등)과 분리시켰습니다.
As-Was Scheduler 코드
@Slf4j
@Component
@RequiredArgsConstructor
public class Sftp1Scheduler {
// Spring Batch Bean
private final JobLauncher jobLauncher;
private final ThreadPoolTaskScheduler threadPoolTaskScheduler;
private final InterfaceFileReaderBatchJobConfig interfaceFileReaderBatchJobConfig;
private final Sftp1Reader sftp1Reader;
// Scheduler 설정 테이블 Jpa Repository
private final SchedulerConfigRepository schedulerConfigRepository;
// Scheduler 식별자
private String schedulerIdx = "3";
private String schedulerName = "Sftp1";
// Scheduler 설정 값
private String executionIp;
private String executionYn;
private String cron;
// Scheduler가 실행시킬 task
private ScheduledFuture<?> future;
// 초기화
@PostConstruct // AP가 실행되고 Spring 초기화 과정에서 메소드가 실행될 수 있도록 선언
public void init() {
try {
if (!this.startScheduler()) {
log.error();
}
}
catch (Exception e) {
log.error();
}
}
// 스케줄러 시작
public boolean startScheduler() throws Exception {
if (this.future != null)
return false;
SchedulerConfig schedulerConfig = schedulerConfigRepository.findBySchedulerIdxAndSchedulerName(this.schedulerIdx, this.schedulerName);
if (!validateExecution(schedulerConfig)) {
return false;
}
this.executionIp = schedulerConfig.getExecutionIp();
this.executionYn = schedulerConfig.getExecutionYn();
this.cron = schedulerConfig.getCron();
ScheduledFuture<?> future = this.threadPoolTaskScheduler.schedule(this.getRunnable(), this.getTrigger());
this.future = future;
return true;
}
// 스케줄러 종료
public void stopScheduler() {
if (this.future != null)
this.future.cancel(true);
this.future = null;
}
// 런타임 스케줄러 주기 변경
public void changeCron(String cron) throws Exception {
this.saveCron(cron);
this.stopScheduler();
this.cron = cron;
this.startScheduler();
}
// 여기부터 클래스 내부에서만 쓸 메소드들
private boolean validateExecution(SchedulerConfig schedulerConfig) throws UnknowsHostException {
if (schedulerConfig == null) {
return false;
}
String localIp = InetAddress.getLocalHost().getHostAddress(); // 현재 실행중인 서버 ip 조회
if ("N".equals(schedulerConfig.getExecutionYn()) || !localIp.equals(schedulerConfig.getExecutionIp())) {
return false;
}
return true;
}
// 스케줄러가 실행시킬 task
private Runnable getRunnable() {
return () -> {
try {
Step interfaceStep = interfaceFileReaderBatchJobConfig.interfaceStep(sftp1Reader.resultFlatFileItemReader);
Map<String, JobParameter> confMap = new HashMap<>();
confMap.put("time", new JobParameter(System.currentTimeMillis()));
JobParameters jobParameters = new JobParameters(confMap);
jobLauncher.run(interfaceFileReaderBatchJobConfig.interfaceJob(interfaceStep), jobParameters);
}
catch (JobExecutionAlreadyRunningException | JobInstanceAlreadyCompleteException | JobParametersInvalidException | JobRestartException e) {
log.error();
}
catch (Exception e) {
log.error();
}
}
}
// 스케줄러의 trigger
private Trigger getTrigger() {
return new CronTrigger(this.cron);
}
@Transactional
private void saveCron(String cron) throws Exception {
SchedulerConfig schedulerConfig = new SchedulerConfig();
schedulerConfig.setSchedulerIdx(this.schedulerIdx);
schedulerConfig.setSchedulerName(this.schedulerName);
schedulerConfig.setCron(cron);
schedulerConfig.setLastChgDt(new Date());
schedulerConfig.setExecutionIp(this.executionIp);
schedulerConfig.setExecutionYn(this.executionYn);
schedulerConfigRepository.save(schedulerConfig);
}
}
To-Be Scheduler 코드
@Slf4j
@Component
@RequiredArgsConstructor
public class CommonScheduler {
private final CommonSchedulerService commonSchedulerService;
private final CommonSchedulerConfigRepository commonSchedulerConfigRepository;
private final ThreadPoolTaskScheduler threadPoolTaskScheduler;
private Map<String, ScheduledFuture<?>> futureMap = new HashMap<>();
private Map<String, Runnable> runnerbleMap = new HashMap<>();
// 초기화 메서드
@PostConstruct
public void init() {
try {
List<CommonSchedulerConfig> commonSchedulerConfigList = commonSchedulerConfigRepository.findAll();
for (CommonSchedulerConfig commonSchedulerConfig : commonSchedulerConfigList) {
switch (commonSchedulerConfig.getSchedulerName()) {
case "changeDateScheduler":
this.runnerbleMap.put("changeDateScheduler", commonSchedulerService::scheduleChangeDate);
if (!this.startScheduler("changeDateScheduler")) {
log.info("changeDateScheduler execution conditions not met");
}
break;
case "autoSendMailScheduler":
this.runnerbleMap.put("autoSendMailScheduler", commonSchedulerService::scheduleAutoSendMail);
if (!this.startScheduler("autoSendMailScheduler")) {
log.info("autoSendMailScheduler execution conditions not met");
}
break;
default:
break;
}
}
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
}
// scheduler 시작 메서드
public boolean startScheduler(String scheduleerName) throws Exception {
CommonSchedulerConfig commonSchedulerConfig = commonSchedulerConfigRepository.findBySchedulerName(scheduleerName);
if (this.futureMap.get(schedulerName) != null)
return false;
if (!this.validateExecution(commonSchedulerConfig, schedulerName)) {
return false;
}
ScheduledFuture<?> future = this.threadPoolTaskScheduler.schedule(this.runnerbleMap.get(schedulerName), new CronTrigger(commonSchedulerConfig.getCron()));
this.futureMap.put(schedulerName, future);
return false;
}
public void stopScheduler(String schedulerName) {
if (this.futureMap.get(schedulerName) != null)
this.futureMap.get(schedulerName).cancel(true);
this.futureMap.remove(schedulerName);
}
public void changeCron(String schedulerName, String cron) throws Exception {
try {
this.saveCron(schedulerName, cron);
this.stopScheduler(schedulerName);
this.startScheduler(schedulerName);
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
}
private boolean validateExecution(CommonSchedulerConfig commonSchedulerConfig, String schedulerName) {
if (commonSchedulerConfig == null) {
log.info("no config data, scheduler : {}", schedulerName);
return false;
}
if ("N".equals(commonSchedulerConfig.getExecutionYn())) {
log.info("execution conditions not met, scheduler : {}", schedulerName);
return false;
}
return true;
}
@Transsactional
private void saveCron(String schedulerName, String cron) throws Exception {
CommonSchedulerConfig commonSchedulerConfig = commonSchedulerConfigRepository.findBySchedulerName(scheduleerName);
commonSchedulerConfig.updateCron(cron);
commonSchedulerConfigRepository.save(commonSchedulerConfig);
}
}
As-Was에서 별개의 클래스로 관리되던 Scheduler를 To-Be에서는 하나의 Scheduler 클래스로 통일하였고, 각각의 클래스에서 관리되던 멤버 변수들은 모두 DB로 관리될 수 있도록 하여, 필요할 때마다 DB에서 조회하여 사용할 수 있도록 수정하였습니다.
그리고 Scheduler가 실행시킬 비즈니스 로직을 해당 클래스의 메서드 형태로 관리하고 있었는데, 이를 변수화 시켜서 Map 자료구조로 Scheduler의 이름과 동작 변수를 매핑시켜서 통합 Scheduler의 멤버변수로 관리하였습니다.
해당 멤버변수의 초기화는 통합 Scheduler 클래스의 초기화 과정이 진행될 때, 모든 Scheduler 목록을 DB로부터 가져오고 사전 작성된 Switch문에서 Scheduler의 이름과 동작을 매핑시키는 과정에서 이루어졌습니다. 이러한 구현에는 () -> void 형태의 함수형 인터페이스 Runnable의 특징을 활용하였습니다.
이렇게 코드를 구성함으로써 스케줄러가 추가될 때마다 Scheduler가 실행시켜야할 비즈니스 로직을 별도 클래스로 구현하고, 통합 Scheduler 클래스의 초기화 메서드에서 Switch 조건만 추가하면 될수 있도록 구현되었습니다. 또한, 스케줄러 동작을 제어하는 API 서비스와 같은 Scheduler 관련 코드도 수정하지 않아도 될 정도로 유지보수의 효율성을 증대시켰습니다.
As-Was SchedulerController 코드
@Controller
@RequiredArgsConstructor
@Slf4j
@RequestMapping("/scheduler")
public class SchedulerController {
// 스케줄러 Bean 주입
private final Sftp1Scheduler sftp1Scheduler;
private final Sftp2Scheduler sftp2Scheduler;
// sheduler 작업 시작
@PostMapping("/start")
@ResponseBody
public ResponseEntity<?> requestStartScheduler(@RequestBody RequestSchedulerDto requestSchedulerDto) throws InterruptedException {
ResponseSchedulerDto responseSchedulerDto = new ResponseSchedulerDto();
String schedulerIdx = responseSchedulerDto.getSchedulerIdx();
String schedulerName = responseSchedulerDto.getSchedulerName();
boolean returnFlag = true;
if (schedulerIdx == null || schedulerName == null) {
responseSchedulerDto.setRsltCd("E1");
responseSchedulerDto.setErrMsg("no request data");
}
try {
if ("1".equals(schedulerIdx) && "InterfaceResult".equals(schedulerName)) {
returnFlag = sftp1Scheduler.startScheduler();
}
else if ("2".equals(schedulerIdx) && "InterfaceResult2".equals(schedulerName)) {
returnFlag = sftp2Scheduler.startScheduler();
}
else {
log.error("no target scheduler");
responseSchedulerDto.setRsltCd("E4");
responseSchedulerDto.setErrMsg("no target scheduler");
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
if (returnFlag == false) {
responseSchedulerDto.setRsltCd("E3");
responseSchedulerDto.setErrMsg("already started scheduler or execution conditions not met");
}
responseSchedulerDto.setRsltCd("S");
responseSchedulerDto.setErrMsg("");
}
catch (Exception e) {
log.error(e.getMessage());
responseSchedulerDto.setRsltCd("E2");
responseSchedulerDto.setErrMsg("internal server error");
}
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
... 코드 생략 ...
}
To-Be ReleaseSchedulerConfigService
@Service
@Slf4j
@RequiredArgsConstructor
public class CommonSchedulerConfigService {
private final CommonScheduler commonScheduler;
public CommonResponse<String> requestStartScheduler(CommonSchedulerConfigReq commonSchedulerConfigReq) {
CommonResponse<String> response = new CommonResponse<>();
if (commonSchedulerConfigReq.getSchedulerName().isEmpty()) {
response.setSuccess(false);
response.setData("필수 파라미터가 누락되었습니다.");
return response;
}
try {
if (commonScheduler.startScheduler(commonSchedulerConfigReq.getSchedulerName())) {
log.error("{}, already started or execution conditions not met", commonSchedulerConfigReq.getSchedulerName());
response.setSuccess(false);
response.setData(commonSchedulerConfigReq.getSchedulerName() + ", already started or execution conditions not met");
}
} catch (Exception e) {
response.setSuccess(false);
response.setData(e.toString());
e.printStackTrace();
}
return response;
}
... 코드 생략 ...
}
위 코드들은 http 요청으로 런타임환경의 Scheduler 동작을 제어할 수 있게하는 Service 로직입니다. To-Be 코드에서 요청 파라미터로 받은 Scheduler의 이름을 통합 Scheduler 클래스의 파라미터로 입력하여 제어할 수 있도록 하였습니다.
이를 통해, 해당 코드에서도 마찬가지로 Scheduler가 추가될 때에도 해당 로직들을 수정하지 않아도 됩니다.