728x90
반응형

AWS Organizations
AWS Organizations : AWS 계정 조직
특징
- 하나의 관리계정, 다수의 기타계정으로 이루어짐
- Organization내 member계정의 비용은 하나의 관리계정에서 지불
- 비용할인은 member계정의 서비스 사용 총액을 기반으로 매겨짐
- reserved instances, saving plan 등 Organization내 다른 계정들과 공유됨 -> 다른 계정에서 사용하지 않는 reserved instance가 있을 경우, 다른 계정이 사용 가능

- 장점
- 다수의 VPC를 가진 단일 계정에 비해 보안이 좋음 -> 계정간 독립성이 좋음
- 모든 계정의 CloudTrail log를 중앙 계정의 S3로 전송가능
- 모든 CloudWatch logs를 중앙 계정으로 전송 가능
- 관리 계정에서 모든 멤버 계정을 관리 가능
- SCP (Service Control Policies) 정의 가능, OU or 계정에 적용되는 IAM 정책 -> 관리계정에는 적용되지 않음 -> IAM 권한은 default가 모든 권한을 허용하지 않음
- SCP는 차단목록과 허용목록 두 가지 전략이 있음
- SCP Example

IAM Conditions
- IAM Conditions : 특정 resource에 대한 IAM Policy의 조건
- aws:SourceIp : API호출에서 Client ID를 제한하는 데 사용
- aws:RequestedRegion : API호출에 대한 region 제한
- ec2:ResourceTag : EC2 인스턴스에 한해 특정 tag를 가지고 있으면 명시되어 있는 action 허용/제한
- aws:PrincipalTag : 해당 tag의 사용자는 명시되어 있는 action 허용/제한
- aws:MultiFactorAuthPresent : MFA 여부에 따라 명시되어 있는 action 허용/제한
- aws:PrincipalOrgID : AWS Organization 멤버 계정에만 리소스정책이 적용되도록 제한 (organization ID 명시 필요)
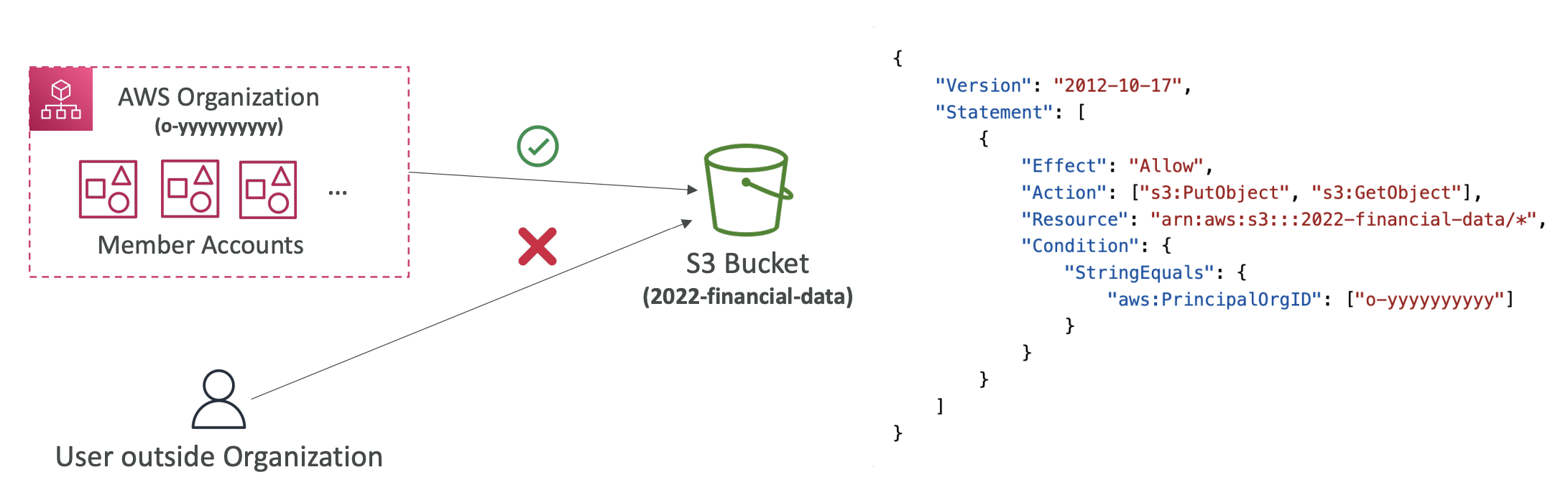
- IAM for S3 (bucket policy)
- bucket 수준의 policy는 bucket을 특정해야 함 -> Resource에 특정 s3 arn(Amazon Resource Number)을 명시하면 됨 (ex. arn:aws:s3:::test -> test bucket)
- 객체 수준의 policy는 object를 특정해야 함 -> ex. arn:aws:s3:::test/* -> test bucket내의 모든 객체
- action example : s3:GetObject, s3:PutObject, s3:DeleteObject
IAM Roles vs Resource Based Policies
Resource Based Policies을 지원하는 서비스 : S3, SNS topic, SQS queue, Lambda, CloudWatch logs, API Gateway etc...
서로 다른 계정간 접근일 경우
- IAM Role을 이용한 접근 : 기존 권한을 모두 버리고 IAM Role을 통해 할당받은 권한만 활용 (기존권한 활용x)
- S3 Bucket Policy를 통한 접근 (Resource Based Policies) : IAM Role을 할당받는 것이 아니기 때문에 기존 권한을 버리지 않음

- Amazon EventBridge를 사용할 때
- target이 Resource Based Policies을 지원하는 서비스일 경우, RBP 설정 필요
- target이 Resource Based Policies을 지원하지 않는 서비스일 경우, EventBridge에 IAM Role 설정 필요

IAM Permission Boundaries
- IAM Permission Boundaries : IAM의 최대 권한을 정의하는 기능, 해당 기능을 특정 IAM User에 할당하게되면, 할당된 권한 Boundary내의 권한만 얻을 수 있음 (Boundary 외의 IAM Role권한을 할당받을 경우, 권한 활용 불가)

- 특징
- user/role에 한함 (group은 지원 안함)
- AWS Organization 권한과 중첩이 된다면?
- Identity-based policy : user나 group에 할당되는 Identity기반 권한
- Permission Boundary : user나 role에 적용
- Organization SCP : 계정 내 모든 IAM User에 적용
-> Effective permission만 행사 가능

- 정책 평가 과정
- Deny가 명시되어 있으면 Deny 우선
- 명시적 Deny가 없어도 명시적 Allow 역시 없으면 실행 불가

AWS Control Tower
AWS Control Tower : 규정을 준수하는 다중 계정의 AWS 환경을 손쉽게 설정하고 관리할 수 있음
AWS Organization을 통해 계정을 자동 생성
정책 위반 감지 및 자동 교정 가능
guardrail을 활용하여 지속적인 정책관리 가능
모든 계정의 규정 준수여부를 대시보드를 통해 모니터링 가능
Guardrail : 특정 항목 일괄 제한 및 특정 유형의 규정 준수여부 모니터링, Control Tower에 대한 모든 계정의 거버넌스 제공
- Prevent Guardrail : Control Tower에서 Organization에 SCP를 사용하도록 강제
- Detective Guardrail : AWS Config 서비스를 활용하여 규정을 준수하지 않는 것을 탐지 (AWS Config 규정준수 여부 탐지 -> Guardrail trigger -> SNS...)

반응형
'개발 > AWS' 카테고리의 다른 글
| [AWS] VPC (Virtual Private Cloud) (0) | 2024.07.06 |
|---|---|
| [AWS] AWS 보안 및 암호화 (1) | 2024.06.30 |
| [AWS] CloudWatch and CloudTail (1) | 2024.06.11 |
| [AWS] AWS Database (1) | 2024.06.08 |
| [AWS] Serverless (Lambda/DynamoDB/API Gateway) (1) | 2024.06.08 |