

Serverless
Serverless : Server가 없는 것은 아니고 관리할 필요가 없음 (서버가 보이지 않거나 provisioning 필요x)
Serverless in AWS
- AWS Lambda
- DynamoDB
- AWS Cognito
- AWS API Gateway
- Amazon S3
- AWS SNS & SQS
- AWS Kinesis Data Firehose
- Aurora Serverless
- Step Functions
- Fargate

AWS Lambda
AWS Lambda : 관리할 서버가 필요없는 코드실행 서비스
특징
- 최대 15분 실행
- 호출을 받을 때, 온디맨드로 실행
- 실행되는 동안에만 비용 청구
- 스케일링 자동화
- 장점
- 쉬운 가격 책정 (요청 횟수 및 컴퓨팅 시간에 따라 책정 -> Lambda가 실행된 만큼)
- Free Tier에서는 요청 백만건과 40GB/s의 컴퓨팅 시간 제공
- 다양한 AWS 서비스와 연결 가능
- 많은 프로그래밍 언어와 호환 -> 오픈소스 덕분
- Node.js
- Python
- Java
- C#
- Golang
- Ruby
- Lambda Container Image -> Container Image 자체가 Lambda의 API가 됨 (Container 상에서 Lambda API가 있어야하기 때문) -> Image에 Lambda API가 없는 경우, ECS나 Fargate에서 Container를 실행하는 것이 더 좋음
- etc...
- CloudWatch와의 통합 쉬움
- 함수당 최대 10GB의 램을 제공받을 수 있음 -> RAM을 증가시키면, CPU 및 네트워크 성능도 같이 좋아짐
- Lambda와의 통합 방식
- API Gateway : Lambda를 호출하는 Rest API 생성
- Kinesis : Lambda를 활용해 데이터 변환
- DynamoDB : DB상에 특정 이벤트가 생기면 Lambda를 실행하도록 트리거를 생성
- S3 : 언제든 Lambda를 실행할 수 있음
- CloudFront : Lambda 전용 CloudFront, Lambda@Edge
- CloudWatch / EventBridge : AWS 인프라이 어떤 일이 생기고 자동 대응을 하려고할 때 활용
- CloudWatch Logs : log를 스트리밍할 때 활용
- SNS : SNS로 알림을 보내고 SNS topic에 따른 처리를 진행할 때 활용
- SQS : SQS Queue 메세지 처리할 때 활용
- Cognito : DB를 활용하여 로그인할 때마다 응답 (인증처리)
- Example1 : Thumbnail creation

- Example2 : Serverless CRON Job
: EC2 등에서 CRON을 활용할 때, 스케줄링이 안되는 시간대에는 낭비가 있어서 Lambda에 활용하는 것이 적절 -> CloudWatch에서 스케줄링 되도록 설정
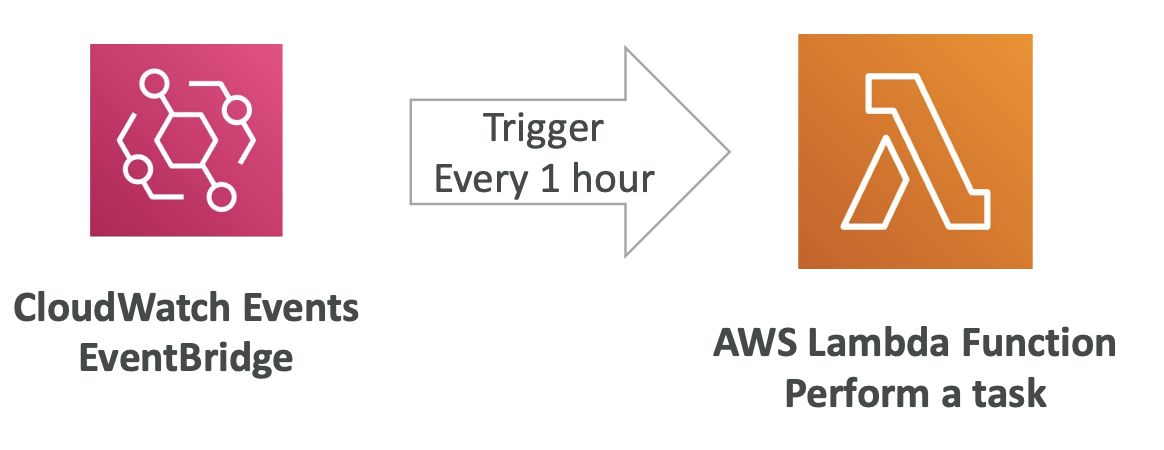
- Lambda Pricing
- 호출당 청구
- 처음 백만건 요청은 무료
- 이후 백만건 마다 20센트 과금
- 기간당 청구 (1ms 단위)
- 한달간 첫 40만GB/s(=1GB RAM을 40만초 사용) 동안은 무료
- 이후에는 60만GB/s당 1달러 과금
Lambda Limits
- 실행한도
- Memory : 128MB ~ 10GB (1MB단위로 증가, CPU성능도 같이 증가)
- 실행시간 : 최대 900초 (15분)
- 환경변수 : 최대 4KB
- 임시공간 : 512MB ~ 10GB (/tmp, 파일처리 등과 같이 공간활용이 필요할 때 사용)
- 동시실행 : 1000개 (미리 예약하고 쓰는 것 권장)
- 배포한도
- 압축 시 50MB, 비압축 시 250MB -> 한도 넘는 경우, /tmp공간 활용 필요
- 배포 후 시작할 때, 크기가 큰 파일이 있을 경우 /tmp 공간 활용 권장
- 환경변수 : 최대 4KB
Lambda SnapStart
Lambda SnapStart : Lambda SnapStart이 활성화 되어 있을 경우, Lambda Function이 미리 초기화된 상태에서 호출 -> 성능 향상
Java11 이상에서 실행되는 Lambda Function의 성능을 추가 비용없이 10배 높여줌
원리 : Lambda Function이 실행되면 메모리와 초기화된 Lambda Function 디스크 상태의 SnapShot 생성됨 -> 생성된 SnapShot은 캐싱되어 다음 Lambda Function 실행 때 활용됨 -> SnapStart
LifeCycle

Edge Function
Edge Function : app에 도달하기 전, Edge에서 특정 logic을 실행하는 Function -> 지연시간 최소화
Edge Function을 사용하면 전역으로 배포되기 때문에 서버관리가 필요하지 않음
Use Case : CrontFront의 CDN 콘텐츠 커스터마이징
CloudFront 함수의 종류
- CloudFront Functions
- Lambda@Edge
- Use Cases
- Dynamic Web Application
- 검색 엔진 최적화 (SEO)
- Origin-DataCenter간 지능형 라우팅
- 엣지에서의 실시간 이미지 변환
- A/B Test
- 사용자 인증 및 인가
- 사용자 우선순위 지정
- 사용자 추적 및 분석
- Website Security and Privacy
- CloudFront Functions
- javascript로 작성된 경량함수
- 확장상이 높고 지연 시간에 민감한 CDN 커스터마이징에 활용
- 최대 실행시간은 1ms 미만 (very simple code), 초당 백만 개의 요청 처리
- 고성능/고확장성, viewer의 요청과 응답을 수정할 때에만 사용
- 모든 코드가 CloudFront에서 직접 관리
- Use Cases
- 캐시 key 정규화 (요청의 attribute를 변환하여 key 변환)
- HTTP 헤더 조작
- URL를 다시 쓰거나 redirect
- 요청 인증 및 인가 (ex. JWT 생성 및 검증 등)
- Lambda@Edge
- Node.JS나 Python으로 작성
- 초당 수천 개의 요청 처리
- 모든 CloudFront 요청 및 응답을 변경할 수 있음 -> Origin 요청/응답도 수정 가능
- us-east-1 region에만 코드 작성 가능 (CloudFront 배포를 관리하는 region과 같은 region -> 함수를 작성하면 CloudFront가 모든 location에 해당 함수 복제)
- 최대 실행시간은 5~10초
- Use Cases
- 여러 라이브러리 로드
- 타사 라이브러리 의존
- SDK로 다른 AWS서비스에 접근
- 네트워크를 통해 외부 서비스에서의 데이터 처리
- 파일 시스템 및 HTTP요청 body에도 접근 가능
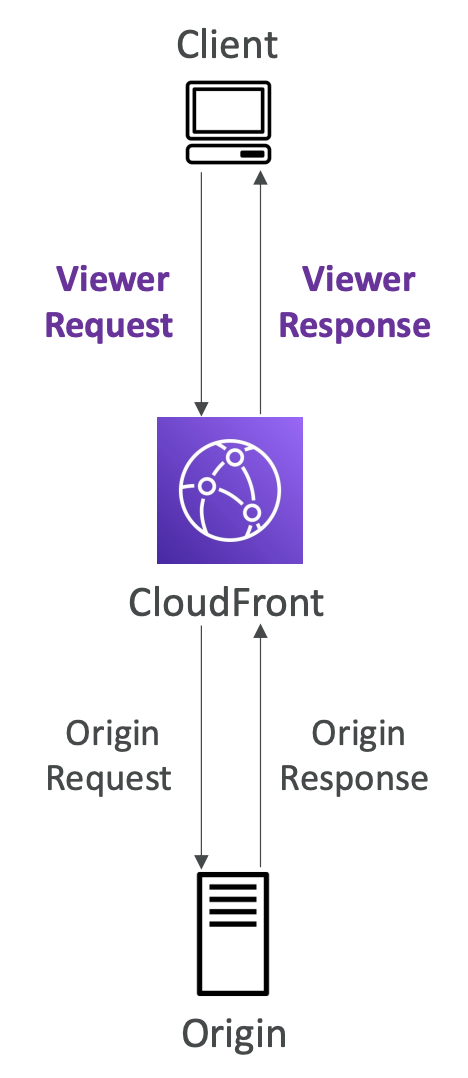
Lambda Network
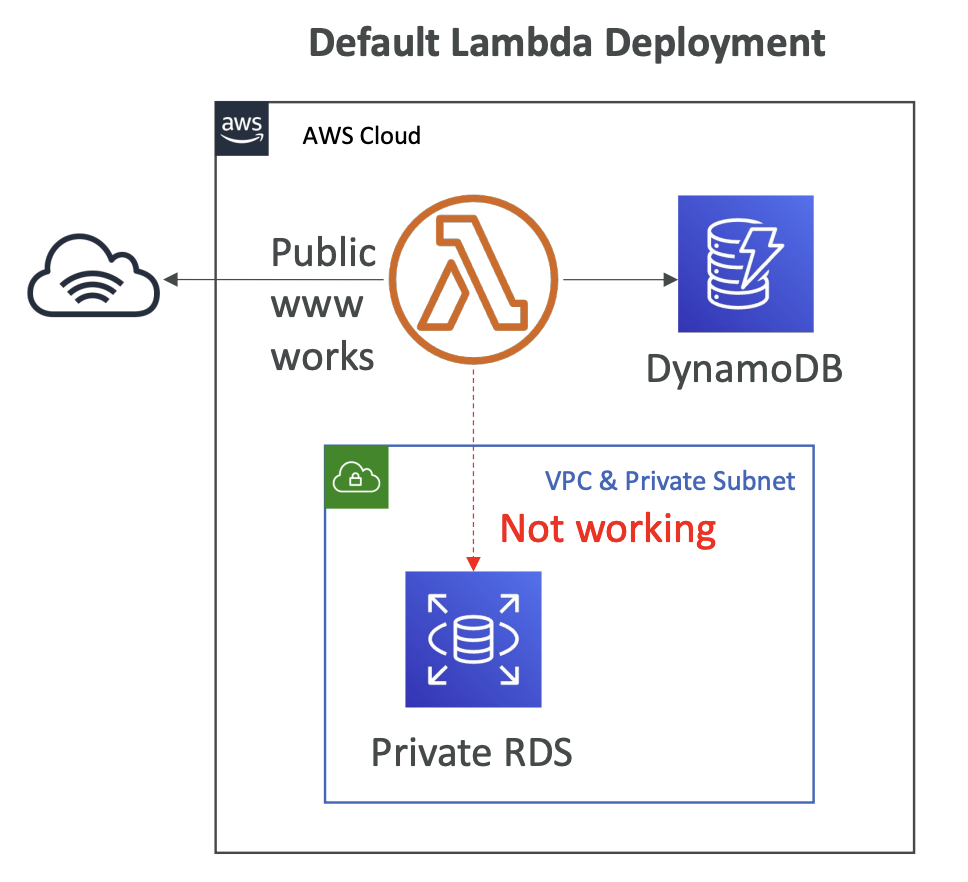
- 기본적으로 Lambda 함수는 VPC 외부에서 시작 -> Lambda는 VPC내부에서 실행되는 AWS 서비스에 접근 불가 -> 인터넷상의 public API 접근 가능 -> VPC내 접근을 위해 VPC에서 Lambda 함수 시작 필요 -> VPC 생성 후 해당 서브넷을 Lambda에 할당하고 보안 그룹 추가 -> 서브넷에 생성된 ENI(Elastic Network Interface)를 통해 VPC 내부 서비스에 접근 가능

- RDS Proxy
- RDS에 Lambda가 직접 접근하게되면, Lambda가 Scale-Out 되었을 때 RDS에 큰 부하를 줄 수 있음 -> RDS Proxy 활용 필요
- DB 연결 pool을 공유함으로써 확장성 향상
- 장애가 발생할 경우에 가용성이 향상되고 연결이 보존됨
- RDS Proxy에서 IAM인증을 강화하여 보안을 높일 수 있고, credential을 Sercets Manager 안에서 관리할 수 있음
- RDS Proxy를 통한 접근을 위해 Lambda는 반드시 동일 VPC내부에 있어야 함 (RDS Proxy는 public에서 접근 불가)

RDS/Aurora에서의 Lambda 호출
- RDS/Aurora에서의 Lambda 호출 : DB에서 일어나는 데이터 이벤트를 처리할 수 있음
- RDS for PostgreSQL/Aurora MySQL에서 지원
- AWS Console 설정이 아님
- RDS DB로부터 Lambda로 오는 트래픽 허용 필요 -> Lambda가 public일 경우, NAT GW/VPC Endpoint 등 사용할 수 있음
- RDS가 Lambda호출할 권한 필요 (IAM 정책 조정 필요)

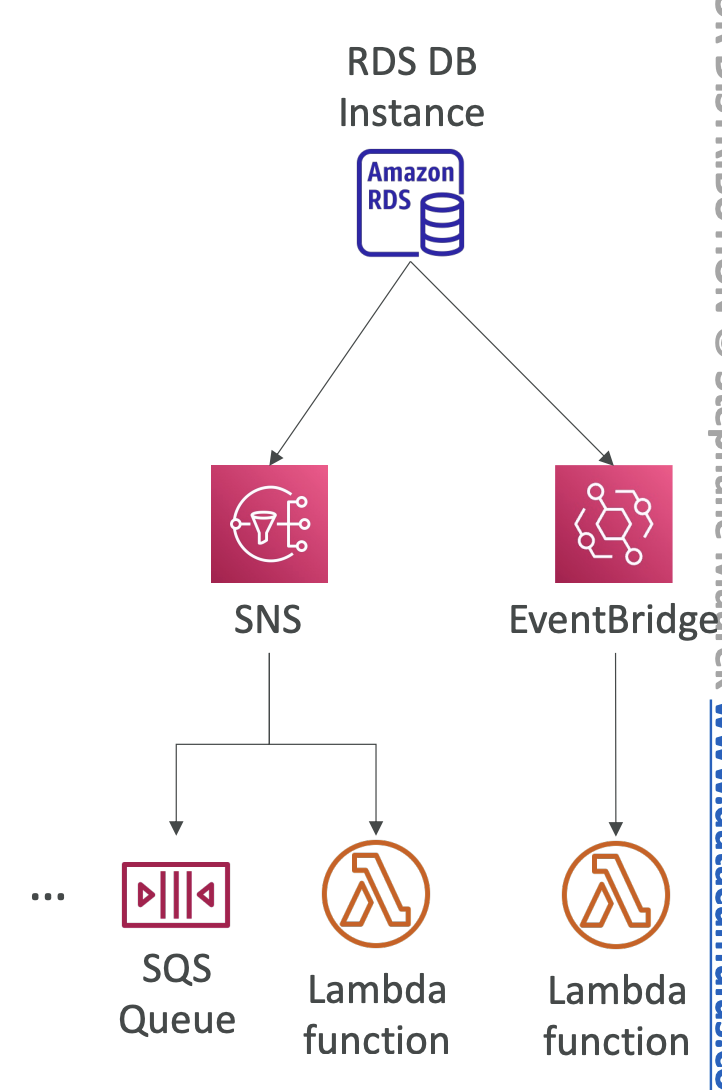
- RDS Event Notifications
- AWS 안에서 DB에 대한 정보(ex. created, stopped, start, etc...)를 알림 (메타데이터?)
- DB안의 데이터는 포함하지 않음 (DB 컬럼정보x) -> DB 컬럼 데이터에 관한 정보는 Lambda를 통해야 함
- 알림 전달 최대 시간 : 5분
- SNS 또는 EventBridge에 전달 가능
DynamoDB
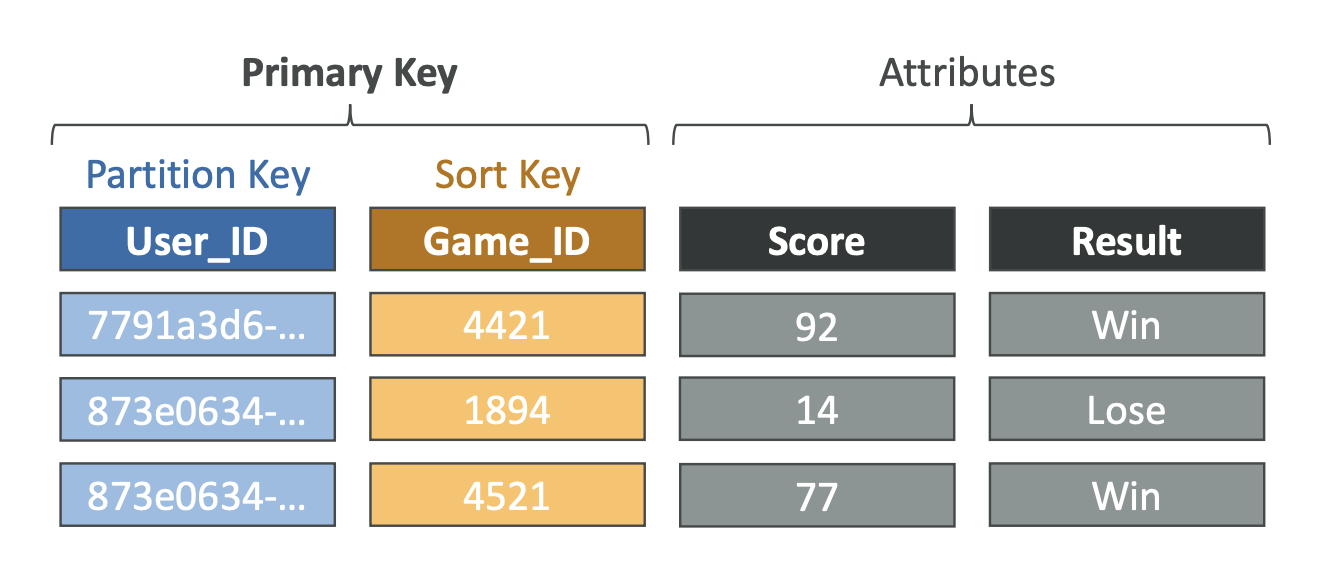
- 특징
- 완전 관리형 DB
- 다중 가용영역에 복제되므로 가용성 좋음
- AWS 독점 NoSQL
- 트랜잭션 지원 기능 있음
- DB가 내부에서 분산되기 때문에 방대한 workload에 적용 가능
- 초당 수백만 개의 요청 처리, 수조개의 rows, 수백 TB 스토리지 -> 성능 좋고, 일관성 높음
- 보안 관련 기능은 IAM 활용
- 비용이 적게 들고, 오토 스케일링 기능이 있음
- 유지관리나 패치가 필요하지 않음
- 테이블 클래스
- Standard : 데이터가 빈번함
- IA : 데이터가 빈번하지 않음
- 기초
- Aurora나 RDS와 달리 DB를 별도 생성하지 않아도 됨 -> DynamoDB는 DB가 이미 존재함
- 테이블로 구성된 DB
- PK는 테이블 생성 시, 결정됨
- 테이블마다 rows를 무한히 추가할 수 있음
- 테이블당 attribute는 열로써 표시됨 -> null이 될 수도 있음
- 열을 언제든 쉽게 추가할 수 있음 -> 각 row에서 attribute 형식이 달라도 됨
- row의 최대 크기는 400KB
- 다양한 데이터 형식 지원
- Scalar : 문자열, 숫자, 바이너리, 불리언, null
- Document : List, Map
- Set : String Set, Number Set, Binary Set
9. DynamoDB는 스키마를 빠르게 적용해야할 때 유용
- Read/Write Capacity Modes
- Provisioned Mode (default)
- 사전에 용량을 Provisioning
- Provisioning된 RCU(Read Capacity Unit)/WCR(Write Capacity Unit)만큼의 비용 지불
- 오토 스케일링 기능이 있어 테이블에 대한 트래픽에 따라 RCU/WCR 조절 가능
- 스키마가 서서히 적용되고, 비용 절감이 필요할 때 활용
- 대충 Workload의 범위 예측 가능 -> 오토 스케일링 기능으로 조절 하면됨
- On-Demand Mode
- 읽기/쓰기 용량이 Workload에 따라 자동 확장
- RCU/WCR 개념이 없음 (미리 Provisioning 하지 않기 때문)
- 사용한 만큼의 비용 지불
- Workload를 예측할 수 없거나 급격히 증가하는 경우에 활용
- Workload 범위도 예측이 안될 경우

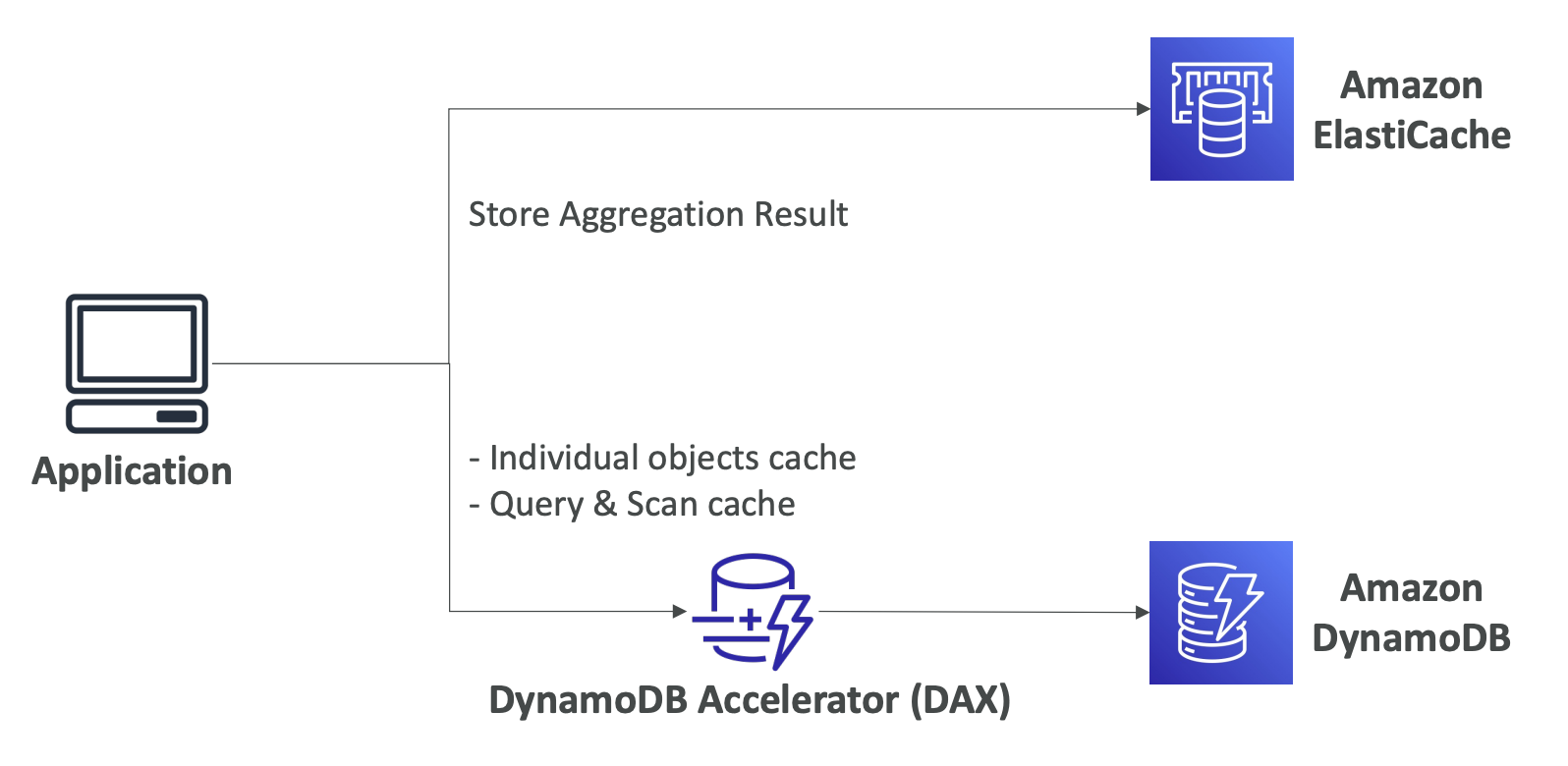
- DynamoDB Accelerator (DAX)
- 완전 관리형 seamless in-memory cache
- 고가용성
- 읽기 작업이 많을 때, DAX 클러스터를 생성하고 데이터를 캐싱함
- ms단위의 저지연 시간의 읽기 성능 제공
- 기존 DynamoDB API와 호환 -> app logic 변경이 필요하지 않음
- TTL은 default로 5분으로 설정되어있으나 변경 가능
- ElastiCache가 아닌 DAX를 사용하는 이유
- 개별 객체에 대한 cache 처리에 유용 -> 집계 결과 처리에는 ElastiCache가 더 좋음
- 쿼리 및 스캔 cache 처리에 유용 -> 대용량의 연산을 저장할 때 좋음
- DynamoDB 앞에 배치
- DynamoDB Stream Processing
- 테이블에 대한 수정사항을 Stream으로 생성할 수 있음 -> 변경사항에 실시간으로 반응
- Use cases
- 사용자 테이블에 새로운 사용자가 등록되었을 때, 환영 이메일 전송
- 실시간 사용 분석
- 파생 테이블 insert
- region간 데이터 복제
- 테이블 변경사항에 대한 Lambda 함수 실행
- Stream 처리의 두 가지 유형
- DynamoDB Streams : 보존기간 24시간, 소비자 수 제한, Lambda 트리거와 주로 사용, 자체적 읽기를 위해 DynamoDB Stream Kinesis 어댑터 사용
- Kinesis Data Streams : 보존기간 1년, 더 많은 소비자 수, 데이터 처리 방법이 다양 (Lambda, Kinesis Data Analytics, Kinesis Data Firehost, Glue Streaming, etc...)

- DynamoDB Global Tables
- 여러 region간 복제 가능 테이블
- 여러 region중 하나의 region의 테이블에 작업을 하면, 다른 region에 복제되어 있는 테이블에도 자동 동기화
- 다수의 region간 복제본을 통해 DynamoDB로의 저지연 접근을 가능하게 함
- 다중 활성 복제 가능 (Active-Active)
- 모든 region에서 테이블에 데이터를 읽고 쓸 수 있음
- DynamoDB Stream 기능 활성화 필요

- DynamoDB Time To Live (TTL)
- 시간이 지나면 자동으로 item(=row)를 삭제하는 기능
- row의 attributes중 하나
- 현재 시간이 TTL상의 시간을 초과하면, 해당 item 삭제 처리
- Backups for disaster recovery
- PITR (point-int-time recovery)를 활용하여 지속적 백업 가능
- 활성화를 선택하면 35일 동안 지속
- 백업기간 내 언제든 복구 수행 가능
- 복구를 진행할 경우, 새로운 테이블 생성
- On-demand backups
- 데이터를 직접 삭제할 때까지 보존
- 테이블의 성능이나 지연시간에 영향을 주지 않음
- 백업 관리 서비스로 AWS Backup이 있음 -> 해당 백업 방식에 lifecycle 홞성화 가능, region간 백업 복제 가능 -> 새로운 테이블 생성
- Amazon S3와의 통합
- S3에 DynamoDB 테이블을 내보내기 위해 PITR 활성화 필수 -> 35일 내에 내보내기 가능
- 쿼리 실행 시, AWS Athena 서비스 활용
- 테이블을 내보내도 테이블의 읽기 용량이나 성능에 영향이 없음
- S3 내보내기를 통한 데이터 분석 가능
- 감사 목적의 snapshot 확보 가능
- S3에서 다시 DynamoDB로 가져올 때 데이터의 대규모 변경 가능
- 내보낼 때, DynamoDB JSON이나 ION형식 이용
- S3에서 테이블을 가져올 때에는 CSV/JSON/ION형식의 객체를 기반으로 새로운 DynamoDB 테이블을 생성하게 됨 -> 쓰기 용량을 소비하지 않고 새로운 테이블 생성
- 가져올 때 발생한 오류는 모두 CloudWatch Logs에 기록
API Gateway
- Client에서도 Lambda를 호출하려면 IAM권한 필요
- ALB와 Lambda의 조합을 활용하게 되면 HTTP endpoint가 노출됨 (서버리스가 아님)

- API Gateway : Client가 Lambda를 호출할 수 있도록 REST API를 제공하는 서버리스 서비스, Lambda 함수에 요청을 Proxy함
- 사용 이유
- 인증 기능 제공
- 사용량 계획 기능 제공
- 개발 환경 기능 제공
- 특징
- Lambda와 결합할 경우, 완전 서버리스
- WebSocket 프로토콜 지원 -> 두 가지 방법의 실시간 스트리밍 가능
- API Versioning을 핸들링 함 (Version 변경이 있어도 client와의 연결이 끊기지 않음)
- dev, test, prod 등 여러 환경 지원
- 여러 보안 기능 제공
- API key 생성 -> client의 요청 조절
- Swagger나 기타 Open API의 공통 표준을 가져올 수 있음 -> 내보낼 수도 있음
- 요청 및 응답의 유효성 검증
- SDK/API 스펙 생성
- API 응답 캐싱
- 통합
- Lambda Function : 서버리스로 Lambda를 client에게 노출시키는 가장 일반적인 방법
- HTTP : 클라우드 환경 및 온프레미스 환경의 백엔드를 HTTP로 노출시킬 수 있음 -> 다양한 공통 기능 추가 (ex. 인증, 캐싱 등)
- AWS Service : 어떤 AWS API도 노출 가능, Step Function workflow 시작, SQS로 메세지 전송
- Use Case (Kinesis Data Streams)
: 사용자가 Kinesis Data Streams에 데이터를 전송할 수는 있지만 AWS 자격증명은 가질 수 없도록 설정

- Endpoint Types (API Gateway 배포방법)
- Edge-Optimized (default)
- global client용
- global하게 접근할 수 있음
- 모든 요청이 CloudFront edge location을 통해 들어옴 -> 지연시간 개선
- API Gateway는 생성된 region에 위치
- Regional
- CloudFront를 원하지 않을 때 활용
- API Gateway와 동일한 region의 사용자만 접근 가능
- 별도로 CloudFront를 배포하여 결합 가능 -> Edge-Optimized 배포와 동일한 결과이지만, CloudFront에 대한 더 많은 권한을 가질 수 있음
- Private
- not Public
- 배포된 VPC내에서만 접근 가능 (ENI와 같은 VPC 인터페이스 활용)
- API Gateway로의 접근을 정의할 때 리소스 정책 사용
- Security
- IAM Role을 사용하여 사용자 식별 -> API Gateway에 접근할 때, IAM Role 사용 필요
- 외부 사용자에 대한 보안 조치로 Amazon Cognito 사용 가능
- 자체로직(ex. Lambda Function)을 구현할 수도 있음 -> Custom Authorizer (사용자 지정 권한 부여자) 활용
- HTTPS의 CDN(Custom Domain Name)을 ACM(AWS Certificate Manager)와 통합 가능
- Edge-Optimized endpoint를 사용할 경우, 인증서는 us-east-1에 있어야 함
- region endpoint를 사용할 경우, 인증서는 API Gateway와 동일한 region에 있어야 함
- Route 53에 CNAME이나 A-alias record를 설정하여 도메인이 API Gateway를 가리키도록 해야 함
Step Functions
- Step Functions : Serverless Workflow를 시각적으로 구성할 수 있는 기능, 주로 Lambda 함수를 설계할 때 활용

- Lambda 함수 뿐만 아니라 EC2 연동, ECS, 온프레미스 서버, API Gateway, SQS 등의 workflow 구조를 표현할 때에도 활용
- Workflow에 사람이 개입하여 승인해야 진행되는 단계를 설정할 수 있음
Amazon Cognito
Amazon Cognito : 사용자에게 웹 및 모바일 앱과 상호작용할 수 있는 자격증명을 제공하는 서비스, 익명의 사용자에게 자격증명을 부여하여 해당 사용자를 인식(Cognito)하게 됨
IAM vs Cognito : Cognito는 AWS 외부의 app 사용자를 대상으로 함 (keywords : 수백명의 사용자, 모바일 사용자, SAML 인증)
Cognito User Pools (CUP)
- 웹 및 모바일 앱을 대상으로 하는 서버리스 사용자 DB
- 이름/이메일/비밀번호 조합으로 간단한 로그인 절차 수립 가능
- 비밀번호 재설정 기능
- 이메일/폰번호 유효성 검증
- Multi-factor Authentication (MFA) 가능
- Facebook, Google, SAML 등 통합 가능 (Federated Identities)
- API Gateway 및 ALB와 통합 가능 -> 유효성 검증 책임을 API Gateway나 ALB에 넘김
- app 사용자에게 가입기능 제공

- Cognito Identity Pools
- 사용자에게 임시 AWS Identity를 부여하여 AWS 계정에 직접 접근 -> 일부 AWS 서비스에 직접 접근 (API Gateway, ALB 직접 접근x)
- Cognito User Pools와 통합 가능
- 타사 로그인 활용 가능 (ex. google 등)
- API Gateway를 통해 AWS 서비스에 접근 가능
- 자격증명에 적용되는 IAM 정책이 Cognito에 사전 정의되어 있음
- User_id 기반으로 사용자를 정의하여 세분화된 제어 가능

- Low Level Security
: DynamoDB Leading key와 Cognito 자격증명 user_id와 같아야 함. -> 해당 조건을 충족시킨 사용자만 DynamoDB 테이블에 접근 가능

'개발 > AWS' 카테고리의 다른 글
| [AWS] CloudWatch and CloudTail (1) | 2024.06.11 |
|---|---|
| [AWS] AWS Database (0) | 2024.06.08 |
| [AWS] AWS Container Service (0) | 2024.06.01 |
| [AWS] SQS, SNS, Kinesis, Active MQ (0) | 2024.06.01 |
| [AWS] AWS Storage (0) | 2024.05.26 |