
![]()
File to DB 개발의 마무리 단계인 Spring Scheduler 개발과정에 대해 정리할 것이다.
이전 게시글까지 File to DB 배치개발은 모두 완료되었다.
대용량의 File 데이터를 읽어서 DB저장하는 부분까지는 우여곡절 끝에 구현하였다. 👉 이전글 참고
아직 남은 요구사항
그리고 아직 남은 요구사항이 있었다.
- File to DB 배치의 실행주기는 관리자가 임의로 조정 가능할 것.
- 관리자의 조정은 런타임 환경에서도 가능해야 함.
- 배치 기능은 실행 서버를 선택할 수 있어야 함.
현재 아래와 같은 @Scheduled 어노테이션 설정 방식으로는 런타임 환경에서 관리자가 임의로 스케줄러 설정을 변경하지 못할 뿐만 아니라,
스케줄러 실행환경도 임의로 선택하지 못한다.
이러한 점을 개선하기 위해 Scheduler 기능의 추가적인 개발이 필요했다.
- JobScheduler.java
@Component
@RequiredArgsConstructor
public class JobScheduler {
private final JobLauncher jobLauncher;
private final InterfaceFileReaderBatchJobConfig interfaceFileReaderBatchJobConfig;
private final InterfaceReader interfaceReader;
// 스케줄러 주기 설정, 어노테이션 선언 방식
@Scheduled(cron = "0 * * * * *")
public void runJob() throws IOException {
...
}
}Scheduler 동작원리
Scheduler 기능 개발에 앞서서 동작원리를 간단하게 살펴본다.
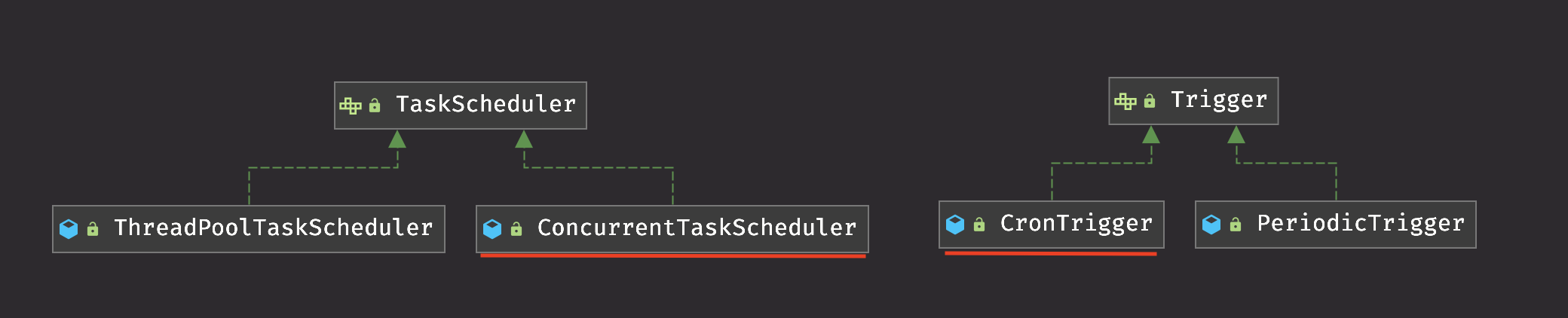
위 사진처럼 Scheduler를 통해 실행될 Task는 TaskScheduler에 주입되어 사용되고, Scheduler의 실행정보는 Trigger에 주입되어 사용된다.
그리고 Scheduler 기능은 위 두가지 추상클래스를 이용하여 실행되는 구조이다.
Scheduler 초기화 순서
- Scheduler가 실행될 root 클래스에 선언된
@EnableScheduling어노테이션을 통해 Scheduler 초기화 작업이 진행된다. @EnableScheduling어노테이션에 import된SchedulingConfiguration클래스가ScheduledAnnotationBeanPostProcessor를 Bean으로 등록 (ScheduledAnnotationBeanPostProcessor을 통해 스케줄링에 필요한 실질적인 초기화 작업이 수행됨 )ScheduledAnnotationBeanPostProcessor클래스가@Scheduled어노테이션이 붙은 메소드를 스케줄러로 등록@Scheduled어노테이션에 설정된 값(ex. fixedDelay, cron 등)에 맞게 task를 생성하여ScheduledTaskRegistrar에 등록, 실제 작업은Runnable에 할당 ( cron 표기법이 사용되었을 경우,CronTrigger가 등록됨 )
위 과정을 통해 ScheduledTaskRegistrar에 task가 등록되면, TaskScheduler가 등록된 task를 일정 주기에 맞게 실행시켜 준다.
TaskScheduler 동작 순서
TaskScheduler클래스의schedule메소드가 파라미터로 task정보를 받아 실행된다.- 일정주기 이후에 실행될 작업을 생성하기 위해 파라미터로 받은 task 정보를 기반으로
ReschedulingRunnable을 생성한다. - 일정주기 이후에
run메소드가 실행되어 작업이 수행되면, 다시schedule메소드를 호출하여ReschedulingRunnable을 생성한다.
(반복)
위 과정이 반복되면서 등록된 task가 일정주기마다 실행된다.
Scheduler 기능 개발 : ThreadPoolTaskScheduler 활용
지금까지 Scheduler의 동작원리를 살펴보았다.
이제 다시 돌아와서, 요구사항을 충족시키기 위해 Scheduler의 추가적인 개발을 진행해보자.
요구사항에 따르면,
Scheduler는 어느 서버에서 실행되어야 하는지, 얼만큼의 주기를 가져야 하는지 런타임 환경에서 조정할 수 있어야 한다.
이를 위해 ThreadPoolTaskScheduler 객체를 활용할 수 있다.
ThreadPoolTaskScheduler란?
ThreadPoolTaskScheduler 는 ConcurrentTaskScheduler 와 같이 TaskScheduler에 등록될 수 있는 Bean이다.
둘 중 ConcurrentTaskScheduler 는 @EnableScheduling 어노테이션을 통해 default로 TaskScheduler에 등록되어,
위에서 언급한 Scheduler 초기화 작업을 수행한다.
다른 하나인 ThreadPoolTaskScheduler 는 사용자가 해당 Bean을 생성하면, @EnableScheduling 어노테이션을 통해 추가적으로 TaskScheduler에 ThreadPoolTaskScheduler Bean도 등록해준다.
그리고 우리는 ThreadPoolTaskScheduler 를 통해 커스터마이징한 Scheduler를 등록할 수 있다.
위와 같이 Scheduler를 커스터마이징할 수 있는 ThreadPoolTaskScheduler 의 강력한 특징을 활용하여 런타임환경에서도 Scheduler의 설정을 변경할 수 있도록 추가적인 기능 개발을 진행할 것이다.
Scheduler 기능 개발 수행
기능 개발을 위해 아래와 같이 코드를 구성하였다.
- ThreadPoolTaskSchedulerConfig.java
@Configuaration
public class ThreadPoolTaskSchedulerConfig {
public ThreadPoolTaskScheduler threadPoolTaskScheduler() {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
taskScheduler.setPoolSize(1); // Scheduler task 실행을 위한 thread의 갯수
taskScheduler.setThreadNamePrefix("jobScheduler"); // thread 이름
taskScheduler.initialize(); // 초기화
return taskScheduler;
}
}위 설정 코드를 통해 Scheduler task 수행을 위한 thread를 몇 개를 생성할지 결정하였다.
아직 Scheduler 기능은 소규모이고, 배치 job들이 비동기로 수행되어 발생되는 예기치못한 오류들을 방지하기 위해
일단 1개만 생성하기로 하였다.
Scheduler task 수행에 멀티스레딩 방식이 필요할 시,
해당 thread의 갯수를 늘리고, 배치 job간 공유하여 사용하고 있는 자원들을 파악하여 멀티스레딩 환경에 맞게 추가개발이 필요할 것이다.
- SchedulerConfig.java
@Table(name = "TB_SCHEDULER_CONFIG")
@Data
@NoArgsConstructor(access = AccessLevel.PUBLIC)
@Entity
public class SchedulerConfig {
@Id
@Column(name = "scheduler_idx", length = 2, nullable = false)
private String schedulerIdx;
@Column(name = "scheduler_name", length = 50, nullable = false)
private String schedulerName;
@Column(name = "cron", length = 50, nullable = false)
private String cron;
@Column(name = "execution_yn", length = 1, nullable = false)
private String executionYn;
@Column(name = "execution_ip", length = 20, nullable = false)
private String executionIp;
@Column(name = "last_chg_dt")
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private Date lastChgDt;
}- SchedulerConfigRepository.java
public interface SchedulerConfigRepository extends JpaRepository<SchedulerConfig, Long> {
SchedulerConfig findBySchedulerIdxAndSchedulerName(String scheduler_idx, String scheduler_name);
}위와 같이 각 Scheduler의 설정정보를 담기 위한 테이블 및 Entity를 생성하였다.
각 필드에 대한 desc은 다음과 같다.
- scheduler_idx : Scheduler를 식별하기 위한 index
- scheduler_name : Scheduler의 이름 (index와 매핑)
- cron : Scheduler 실행 주기를 결정할 cron식
- execution_yn : AP 내부에서의 Scheduler 실행여부를 결정
- execution_ip : Scheduler가 실행될 서버의 ip
- last_chg_dt : 설정 최종변경 일시
런타임환경 실행주기 변경, 특정 서버에서만 실행, 실행 여부 변경이라는 요구사항을 충족시키기 위해
위와 같이 설정테이블을 구성한 것이다.
그리고 각 Scheduler가 위 테이블에 저장된 설정 값을 기반으로 실행될 수 있도록 Scheduler 코드를 작성할 것이다.
- Sftp1Scheduler.java
@Slf4j
@Component
@RequiredArgsConstructor
public class Sftp1Scheduler {
// Spring Batch Bean
private final JobLauncher jobLauncher;
private final ThreadPoolTaskScheduler threadPoolTaskScheduler;
private final InterfaceFileReaderBatchJobConfig interfaceFileReaderBatchJobConfig;
private final Sftp1Reader sftp1Reader;
// Scheduler 설정 테이블 Jpa Repository
private final SchedulerConfigRepository schedulerConfigRepository;
// Scheduler 식별자
private String schedulerIdx = "3";
private String schedulerName = "Sftp1";
// Scheduler 설정 값
private String executionIp;
private String executionYn;
private String cron;
// Scheduler가 실행시킬 task
private ScheduledFuture<?> future;
// 초기화
@PostConstruct // AP가 실행되고 Spring 초기화 과정에서 메소드가 실행될 수 있도록 선언
public void init() {
try {
if (!this.startScheduler()) {
log.error();
}
}
catch (Exception e) {
log.error();
}
}
// 스케줄러 시작
public boolean startScheduler() throws Exception {
if (this.future != null)
return false;
SchedulerConfig schedulerConfig = schedulerConfigRepository.findBySchedulerIdxAndSchedulerName(this.schedulerIdx, this.schedulerName);
if (!validateExecution(schedulerConfig)) {
return false;
}
this.executionIp = schedulerConfig.getExecutionIp();
this.executionYn = schedulerConfig.getExecutionYn();
this.cron = schedulerConfig.getCron();
ScheduledFuture<?> future = this.threadPoolTaskScheduler.schedule(this.getRunnable(), this.getTrigger());
this.future = future;
return true;
}
// 스케줄러 종료
public void stopScheduler() {
if (this.future != null)
this.future.cancel(true);
this.future = null;
}
// 런타임 스케줄러 주기 변경
public void changeCron(String cron) throws Exception {
this.saveCron(cron);
this.stopScheduler();
this.cron = cron;
this.startScheduler();
}
// 여기부터 클래스 내부에서만 쓸 메소드들
private boolean validateExecution(SchedulerConfig schedulerConfig) throws UnknowsHostException {
if (schedulerConfig == null) {
return false;
}
String localIp = InetAddress.getLocalHost().getHostAddress(); // 현재 실행중인 서버 ip 조회
if ("N".equals(schedulerConfig.getExecutionYn()) || !localIp.equals(schedulerConfig.getExecutionIp())) {
return false;
}
return true;
}
// 스케줄러가 실행시킬 task
private Runnable getRunnable() {
return () -> {
try {
Step interfaceStep = interfaceFileReaderBatchJobConfig.interfaceStep(sftp1Reader.resultFlatFileItemReader);
Map<String, JobParameter> confMap = new HashMap<>();
confMap.put("time", new JobParameter(System.currentTimeMillis()));
JobParameters jobParameters = new JobParameters(confMap);
jobLauncher.run(interfaceFileReaderBatchJobConfig.interfaceJob(interfaceStep), jobParameters);
}
catch (JobExecutionAlreadyRunningException | JobInstanceAlreadyCompleteException | JobParametersInvalidException | JobRestartException e) {
log.error();
}
catch (Exception e) {
log.error();
}
}
}
// 스케줄러의 trigger
private Trigger getTrigger() {
return new CronTrigger(this.cron);
}
@Transactional
private void saveCron(String cron) throws Exception {
SchedulerConfig schedulerConfig = new SchedulerConfig();
schedulerConfig.setSchedulerIdx(this.schedulerIdx);
schedulerConfig.setSchedulerName(this.schedulerName);
schedulerConfig.setCron(cron);
schedulerConfig.setLastChgDt(new Date());
schedulerConfig.setExecutionIp(this.executionIp);
schedulerConfig.setExecutionYn(this.executionYn);
schedulerConfigRepository.save(schedulerConfig);
}
}위와 같이 Scheduler 코드를 작성하여 런타임 환경에서 사용자 임의대로 스케줄러 설정을 변경할 수 있도록 하였다.
초기화 flow는 다음과 같다.
초기화 flow
- AP 실행 및 Spring 초기화
- init 메소드 실행
- startScheduler 메소드 실행
- 스케줄러 설정 테이블 값 조회
- 조회 값 기반 validateExecution 메소드 실행
- 서버ip, 실행여부 확인 및 결정
- threadPoolTaskScheduler.schedule 실행
- 다음 주기에 실행될 task 등록
- 다음 주기에 실행될 task 등록
- startScheduler 메소드 실행
- init 메소드 실행
일단 위 코드를 통해 임의 서버에서 실행여부에 맞게 Scheduler가 실행되도록 startScheduler, validateExecution 메소드를 작성하였다.
그리고 changeCron 및 stopScheduler 메소드를 작성하여 런타임환경에서 사용자의 요청에 따라 Scheduler를 제어할 수 있도록 준비하였다.
이제 실제로 사용자의 요청을 받기 위한 Controller 구현이 필요했다.
- RequestSchedulerDto.java
@Data
public class RequestSchedulerDto {
@JsonProperty("schedulerIdx")
private String schedulerIdx;
@JsonProperty("schedulerName")
private String schedulerName;
@JsonProperty("cron")
private String cron;
}- ResponseSchedulerDto.java
@Data
public class ResponseSchedulerDto {
@JsonProperty("rsltcd")
private String rsltCd;
@JsonProperty("errMsg")
private String errMsg;
}- SchedulerController.java
@Controller
@RequiredArgsConstructor
@Slf4j
@RequestMapping("/scheduler")
public class SchedulerController {
// 스케줄러 Bean 주입
private final Sftp1Scheduler sftp1Scheduler;
private final Sftp2Scheduler sftp2Scheduler;
// sheduler 작업 시작
@PostMapping("/start")
@ResponseBody
public ResponseEntity<?> requestStartScheduler(@RequestBody RequestSchedulerDto requestSchedulerDto) throws InterruptedException {
ResponseSchedulerDto responseSchedulerDto = new ResponseSchedulerDto();
String schedulerIdx = responseSchedulerDto.getSchedulerIdx();
String schedulerName = responseSchedulerDto.getSchedulerName();
boolean returnFlag = true;
if (schedulerIdx == null || schedulerName == null) {
responseSchedulerDto.setRsltCd("E1");
responseSchedulerDto.setErrMsg("no request data");
}
try {
if ("1".equals(schedulerIdx) && "InterfaceResult".equals(schedulerName)) {
returnFlag = sftp1Scheduler.startScheduler();
}
else if ("2".equals(schedulerIdx) && "InterfaceResult2".equals(schedulerName)) {
returnFlag = sftp2Scheduler.startScheduler();
}
else {
log.error("no target scheduler");
responseSchedulerDto.setRsltCd("E4");
responseSchedulerDto.setErrMsg("no target scheduler");
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
if (returnFlag == false) {
responseSchedulerDto.setRsltCd("E3");
responseSchedulerDto.setErrMsg("already started scheduler or execution conditions not met");
}
responseSchedulerDto.setRsltCd("S");
responseSchedulerDto.setErrMsg("");
}
catch (Exception e) {
log.error(e.getMessage());
responseSchedulerDto.setRsltCd("E2");
responseSchedulerDto.setErrMsg("internal server error");
}
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
// scheduler 작업 종료
@PostMapping("/stop")
@ResponseBody
public ResponseEntity<?> requestStopScheduler(@RequestBody RequestSchedulerDto requestSchedulerDto) throws InterruptedException {
ResponseSchedulerDto responseSchedulerDto = new ResponseSchedulerDto();
String schedulerIdx = responseSchedulerDto.getSchedulerIdx();
String schedulerName = responseSchedulerDto.getSchedulerName();
if (schedulerIdx == null || schedulerName == null) {
responseSchedulerDto.setRsltCd("E1");
responseSchedulerDto.setErrMsg("no request data");
}
try {
if ("1".equals(schedulerIdx) && "InterfaceResult".equals(schedulerName)) {
returnFlag = sftp1Scheduler.stopScheduler();
}
else if ("2".equals(schedulerIdx) && "InterfaceResult2".equals(schedulerName)) {
returnFlag = sftp2Scheduler.stopScheduler();
}
else {
log.error("no target scheduler");
responseSchedulerDto.setRsltCd("E4");
responseSchedulerDto.setErrMsg("no target scheduler");
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
responseSchedulerDto.setRsltCd("S");
responseSchedulerDto.setErrMsg("");
}
catch (Exception e) {
log.error(e.getMessage());
responseSchedulerDto.setRsltCd("E2");
responseSchedulerDto.setErrMsg("internal server error");
}
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
// cron식 변경
@PostMapping("/changecron")
@ResponseBody
public ResponseEntity<?> requestChangeTrigger(@RequestBody RequestSchedulerDto requestSchedulerDto) throws InterruptedException {
ResponseSchedulerDto responseSchedulerDto = new ResponseSchedulerDto();
String schedulerIdx = responseSchedulerDto.getSchedulerIdx();
String schedulerName = responseSchedulerDto.getSchedulerName();
String cron = responseSchedulerDto.getCron();
if (schedulerIdx == null || schedulerName == null || cron == null) {
responseSchedulerDto.setRsltCd("E1");
responseSchedulerDto.setErrMsg("no request data");
}
try {
if ("1".equals(schedulerIdx) && "InterfaceResult".equals(schedulerName)) {
returnFlag = sftp1Scheduler.changeCron();
}
else if ("2".equals(schedulerIdx) && "InterfaceResult2".equals(schedulerName)) {
returnFlag = sftp2Scheduler.changeCron();
}
else {
log.error("no target scheduler");
responseSchedulerDto.setRsltCd("E4");
responseSchedulerDto.setErrMsg("no target scheduler");
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
responseSchedulerDto.setRsltCd("S");
responseSchedulerDto.setErrMsg("");
}
catch (Exception e) {
log.error(e.getMessage());
responseSchedulerDto.setRsltCd("E2");
responseSchedulerDto.setErrMsg("internal server error");
}
return new ResponseEntity<>(responseSchedulerDto, HttpStatus.OK);
}
}위와 같이 코드를 작성하여 실제 사용자가 scheduler 작업을 controll 할 수 있게 하였다.
Controller는 아래와 같이 3개로 구성하였다.
- requestStartScheduler
- requestStopScheduler
- requestChangeTrigger
Controller의 구성은 셋 다 비슷한데, 기본적인 flow는 아래와 같다.
- Rest API body 값을 읽어서 사용자의 요청 값을 받는다.
- 받은 요청 값을 통해 어떤 Scheduler를 실행시킬지 결정한다. (if-else)
- Scheduler가 결정되면, 요청에 맞는 Scheduler의 메소드를 실행시킨다.
개선할 점.
- Scheduler 클래스 -> 인터페이스 및 부모-자식 클래스로 변경
: 각 Scheduler 클래스의 구성은 비슷하다. Interface 및 부모-자식 클래스로 리팩토링 하여
코드의 양을 현저하게 줄이고, 코드의 유지보수성을 높일 수 있다. 그리고 이를 통해 Controller의 if-else문을 개선할 수 있을 것 같다. - Controller if-else
: 현행은 if-else문을 통해 Scheduler를 식별하는 방식이다. 위 1번 항목에서 리팩토링된 코드를 활용하면
scheduler가 추가될 때마다 else if를 추가하지 않아도 작동될 수 있도록 개발할 수 있지않을까 생각된다. => 검토 필요
위에서 언급한 개선 점은 👉다음글에서 어느정도 보완하였다.
마무리
본 글을 마지막으로 File to DB 개발기를 끝낸다.
이외에도 비대면 고객케어 솔루션 프로젝트를 통해 개발한 부분이 있다. (Spring Security, SOAP연동)
해당 부분은 좀 더 정리가 되면 이어서 작성할 것이다.
File to DB 개발을 수행했던 3월 한달 간 너무나 재밌고 유익한 개발을 경험했다.
Spring Boot의 기본 동작원리 뿐만 아니라, Scheduler, Batch 등과 같은 Spring 모듈에 대해서도 알게되어 좋았다.
또, 개발하며 느낀건... 내가 미지의 부분을 개발하며 하나씩 알아가는 것에 재미를 느낀다는 것을 알게 되었다.
개발하며 결과물을 내는 것도 좋지만, 앞으로는 개발을 진행하며 궁금증을 하나씩 해소해 나가는 과정에 초점을 두어야겠다.
그리고 이를 통해 꾸준하게 성장해 나갈 것이다.
'개발 > Spring Framework' 카테고리의 다른 글
| [Spring] JPA, 효율적으로 데이터 누락없이 DB update 하기 (1) | 2024.01.13 |
|---|---|
| [Spring] Spring Scheduler 좀 더 세련되게 만들기 (feat. 함수형 인터페이스) (0) | 2024.01.13 |
| [Spring] Spring Batch - File to DB 개발 (2) (1) | 2023.04.28 |
| [Spring] Spring Batch - File to DB 개발 (1) (0) | 2023.04.19 |
| [Spring] Spring Batch란? (0) | 2023.04.09 |



